Adversarial Robustness
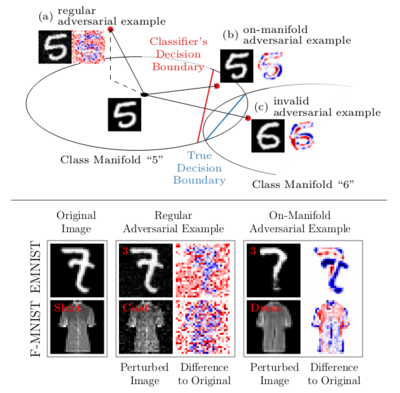
Disentangling Adversarial Robustness and Generalization
Obtaining deep networks that are robust against adversarial examples and generalize well is an open problem. A recent hypothesis even states that both robust and accurate models are impossible, i.e., adversarial robustness and generalization are conflicting goals. In an effort to clarify the relationship between robustness and generalization, we assume an underlying, low-dimensional data manifold and show that: 1. regular adversarial examples leave the manifold; 2. adversarial examples constrained to the manifold, i.e., on-manifold adversarial examples, exist; 3. on-manifold adversarial examples are generalization errors, and on-manifold adversarial training boosts generalization; 4. regular robustness and generalization are not necessarily contradicting goals. These assumptions imply that both robust and accurate models are possible. However, different models (architectures, training strategies etc.) can exhibit different robustness and generalization characteristics. To confirm our claims, we present extensive experiments on synthetic data (with known manifold) as well as on EMNIST, Fashion-MNIST and CelebA.
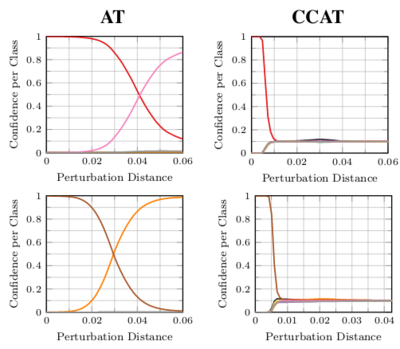
Confidence-Calibrated Adversarial Training
Adversarial training yields robust models against a specific threat model, e.g., L∞ adversarial examples. Typically robustness does not generalize to previously unseen threat models, e.g., other Lp norms, or larger perturbations. Our confidence-calibrated adversarial training (CCAT) tackles this problem by biasing the model towards low confidence predictions on adversarial examples. By allowing to reject examples with low confidence, robustness generalizes beyond the threat model employed during training. CCAT, trained only on L∞ adversarial examples, increases robustness against larger L∞, L2, L1 and L0 attacks, adversarial frames, distal adversarial examples and corrupted examples and yields better clean accuracy compared to adversarial training. For thorough evaluation we developed novel white- and black-box attacks directly attacking CCAT by maximizing confidence. For each threat model, we use 7 attacks with up to 50 restarts and 5000 iterations and report worst-case robust test error, extended to our confidence-thresholded setting, across all attacks.

Adversarial Training against Location-Optimized Adversarial Patches
Deep neural networks have been shown to be susceptible to adversarial examples -- small, imperceptible changes constructed to cause mis-classification in otherwise highly accurate image classifiers. As a practical alternative, recent work proposed so-called adversarial patches: clearly visible, but adversarially crafted rectangular patches in images. These patches can easily be printed and applied in the physical world. While defenses against imperceptible adversarial examples have been studied extensively, robustness against adversarial patches is poorly understood. In this work, we first devise a practical approach to obtain adversarial patches while actively optimizing their location within the image. Then, we apply adversarial training on these location-optimized adversarial patches and demonstrate significantly improved robustness on CIFAR10 and GTSRB. Additionally, in contrast to adversarial training on imperceptible adversarial examples, our adversarial patch training does not reduce accuracy.