Deep Gaze Pooling: Inferring and Reconstructing Search Intent From Human Fixations
Hosnieh Sattar, Andreas Bulling, Mario Fritz
Abstract

Predicting the target of visual search from eye fixation (gaze) data is a challenging problem with many applications in human-computer interaction. In contrast to previous work that has focused on individual instances as a search target, we propose the first approach to predict categories and attributes of search targets based on gaze data and to even visualize a plausible search target. However, state-of-the-art models for categorical recognition, in general, require large amounts of training data, which is prohibitive for gaze data. To address this challenge, we further propose a novel Gaze Pooling Layer that combines gaze information with visual representations from Deep Learning approaches. Our scheme incorporates both spatial and temporal aspects of human gaze behavior as well as the appearance of the fixated locations. We propose an experimental setup and data set and demonstrate the effectiveness of our method for search target prediction and visualization based on gaze behavior. We highlight several practical advantages of our approach, such as compatibility with existing architectures, no need for gaze training data, and robustness to noise from typical gaze sources.
Data Collection and Collage Synthesis
No existing data set provides image and gaze data that is suitable for our search target prediction task. We therefore collected our own gaze data set based on the DeepFashion data set. DeepFashion is a clothes data set consisting of 289,222 images annotated with 46 different categories and 1,000 attributes. We used the top 10 categories and attributes in our data collection. The training set of DeepFashion was used to train our CNN image model for clothes category and attribute prediction; the validation set was used to train participants for each category and attribute Finally, the test set was used to build up image collages for which we recorded human gaze data of participants while searching for specific categories and attributes.
Participants, Apparatus, and Procedure
We collected data from 14 participants (six females), aged between 18 and 30 years and with different nationalities. All of them had normal or corrected-to-normal vision. For gaze data collection we used a stationary Tobii TX300 eye tracker that provides binocular gaze data at a sampling frequency of 300Hz. We calibrated the eye tracker using a standard 9-point calibration, followed by a validation of eye tracker accuracy. For gaze data processing we used the Tobii software with the parameters for fixation detection left at their defaults (fixation duration: 60ms, maximum time between fixations: 75ms). Image collages were shown on a 30-inch screen with a resolution of 2560x1600 pixels.
Method
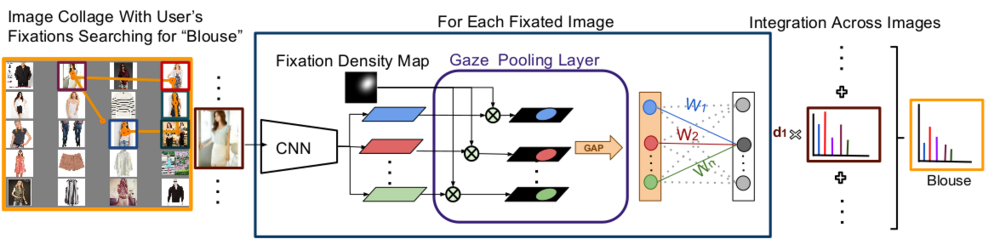
In this work, we are interested in predicting the category and attributes of search targets from gaze data. We address this task by introducing the Gaze Pooling Layer (GPL) that combines CNN architectures with gaze data in a weighting mechanism -- a new encoding of fixation data that integrates seamlessly with state-of-the-art deep learning approaches. The major components of our method are: The image encoder, human gaze encoding, the Gaze Pooling Layer, and search target prediction. Int this work, we also discuss different integration schemes across multiple images that allow us to utilize gaze information obtained from collages. As a mean of inspecting the internal representation of our Gaze Pooling Layer, we propose Attended Class Activation Maps (ACAM).