Benchmarking congestion-control algorithms
Network congestion, the state where nodes receive more data than they can handle, leads to packet losses, increased network delay and reduced throughput for all data flows passing through a congested node. Despite four decades of research on congestion-control algorithms or schemes, there is yet no “one-size fits-all" solution. There are at least 30 different congestion-control algorithms as of today, and new ones are still being proposed every so often. Determining how any one scheme falls short in comparison to the rest, and, most importantly, along what dimensions, is quite difficult to answer. Even performing all the pairwise comparisons between the schemes is hard because each algorithm behaves differently depending on the underlying network environment. Additionally, determining under what regime (i.e., combination of network latency, buffer sizes, bandwidth, etc.) a given scheme
fares better or worse compared to another has proven to be challenging.
To address the above, we have proposed a congestion-control benchmark platform. In a benchmarking test, network conditions get worse if the protocol performs well, and better if it does not. In this way, the benchmark platform is able to identify conditions where a protocol performs optimally; and by creating situations where a protocol does worse, helps show why this is the case. The work in the paper "Pantheon: the training ground for Internet congestion-control, published at NSDI ’15, took the initial steps towards formally addressing the lack of a platform for evaluating congestion-control algorithms. The Pantheon allows congestion-control algorithms to be tested in a reproducible manner and serves as ‘training ground’ for newer algorithms. There are, however, many open research
challenges that still need to be addressed.
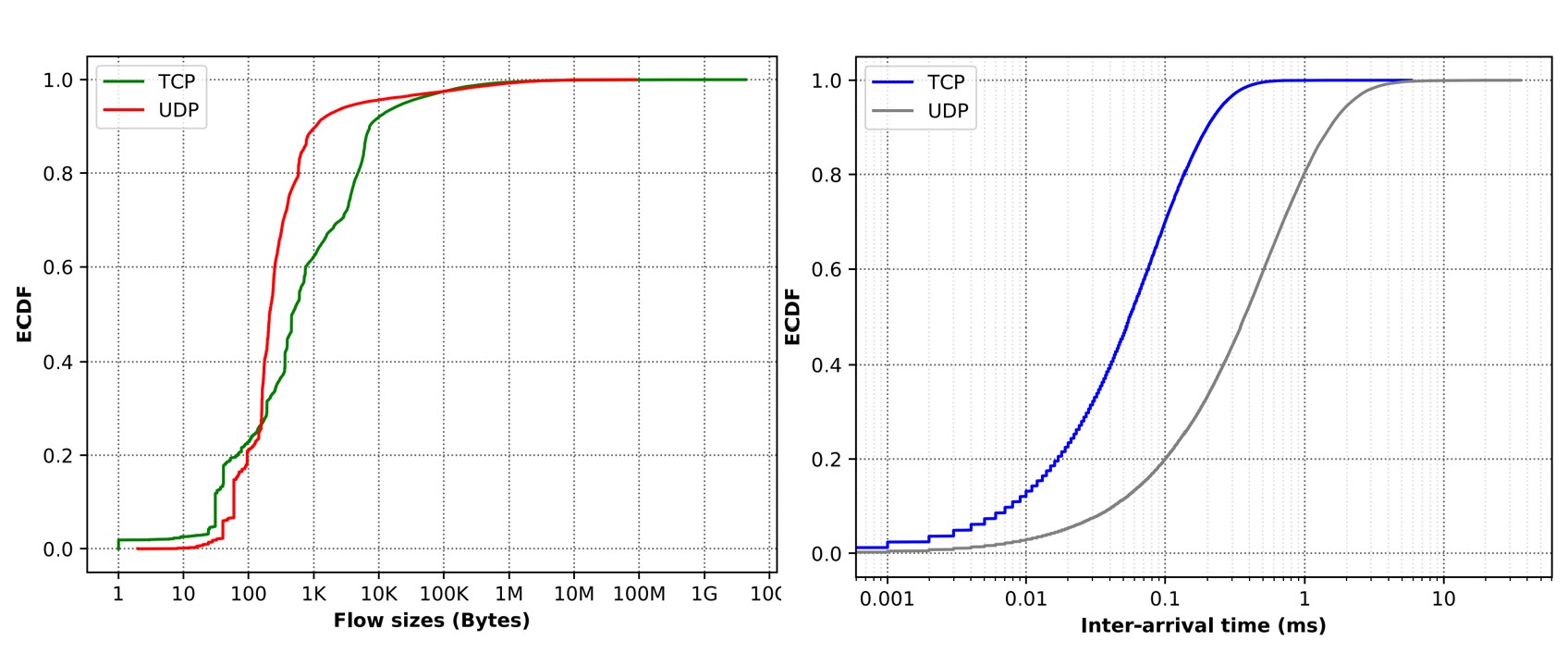
The first goal of our project is to extend the Pantheon to test congestion-control schemes along several dimensions. To address some of the missing functionalities with the original Pantheon codebase, we have implemented several features including the ability to emulate per-flow delay, the ability to run large batch experiments and the ability to run byte size limited flows. The second major goal of the project is determining how to efficiently explore the high-dimensional experiment-configuration space. When evaluating TCP mechanisms like congestion control, it is important to use real-world traffic characteristics to ensure that the performance of the congestion-control algorithm in the emulated environment is as close as possible to what its performance will be in the real Internet. As an initial step towards this goal, we have analyzed passive, anonymized Internet traffic traces captured on a backbone link of a Tier1 ISP between New York, USA and Sao Paolo, Brazil. The analyzed statistics were such as flow inter-arrival time and flow size distribution as seen in the figure below.
Performing this analysis does not only give us a realistic composition of evaluation parameters for our benchmark, we also confirmed the ‘elephant’ and ‘mice’ flow attributes of Internet traffic. Mice flows are flows that transfer a small total number of bytes (i.e less than 10 KB) and are short-lived. Elephant flows on the other hand are large, long-lived
flows. From the analysis, we saw that while mice flows dominate in terms of number of flows, elephant flows dominate by volume of data transferred. This means that while elephant flows are congestion-controlled, mice flows are not, and may therefore fill up network buffers on-path, negatively impacting elephant flows. Towards meeting the objective of fairly sharing on-path network resources between mice and elephant flows, current work involves using the extended platform to evaluate how various congestion-control algorithms handle mice and elephant flows under different network conditions. We plan to extend these experiments to lab-based hardware tests as well as in the
wild (i.e in the public Internet). Our findings should help identify which congestion-control algorithm better handles interactions between mice and elephant flows. Additional questions that we hope to answer as part of this ongoing project include:
1. Can we use online learning to sample the high-dimensional experiment-configuration space and what learning algorithm is appropriate for sampling such a parameter space?
2. In what situations are current congestion-control algorithms fair to one another and when should we expect fairness?
3. What performance metrics should we consider when evaluating congestion control?