Making computers know how much they know.
Automated knowledge extraction and consolidation is an important step towards building intelligent and knowledge-grounded applications. In large projects such as NELL, DBpedia or Yago, machines automatically read web contents and consolidate them into encyclopedic representations of reality. A major limitation of these knowledge bases is that they do not contain information on how much they actually know.
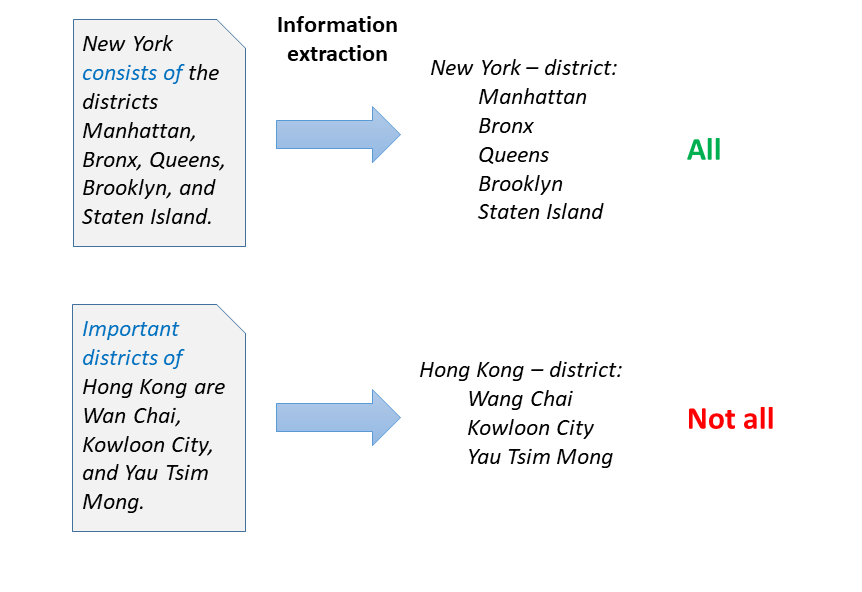
Consider the sentences in the figure. From these two sentences, text extraction (NLP) methods can easily extract 5 and 3 districts of New York and Hong Kong, respectively. Would the machine then know all districts?
In our research, we are enabling machines to understand how much they know,
(i) by mining cardinality bounds for information,
(ii) by utilizing linguistic theories of human communication for coverage estimation.
In mining cardinality bounds, we build information extraction methods that target numerical information in texts, and link it with actual extractions. For the above example, a sentence like ``Hong Kong is divided into 17 districts'' would provide the crucial cue: The listed names thus represent 3 of the 17 districts. Our method relies on sequence tagging algorithms such as CRFs and LSTMs, and can successfully overcome challenges like skewed training data, compositionality (``consists of 5 metropolitan and 12 rural districts''), and hierarchical differentiation (``consists of 4 boroughs, which are further divided into 17 districts and 57 councils'').
In utilizing linguistic theories of communication, we build upon Grice's maxims of cooperative communication. According to these, speakers balance their speech acts between quantity (``tell what you know''), and relevance (``tell what matters''). So context is decisive: A tourist guide may naturally focus on important districts, an encyclopedic description will strive towards covering all. To identify the focus of a context, we build text classifiers that detect trigger words and topics that indicate the coverage of texts towards specific relations. In the examples, important trigger words are ``important districts'' (so probably not all), and ``consists of'' (a term typically used before complete enumerations). Our models can succesfully estimate the coverage of varied relations like ``district'', ``part of'' (of artwork), ``child'', or ``member of'' (of bands).
Both approaches complement each other, and enable machines that have an understanding of the strengths and limitations of their knowledge. This understanding is important both in applications such as question answering (where machines should point out if they are unsure of an answer), as well as automated knowledge base construction itself, where only with awareness of gaps it is possible to properly focus further extraction efforts.
[1] Cardinal Virtues: Extracting Relation Cardinalities from Text. Paramita Mirza, Simon Razniewski, Fariz Darari, Gerhard Weikum. ACL 2017
[2] Enriching Knowledge Bases with Counting Quantifiers. Paramita Mirza, Simon Razniewski, Fariz Darari and Gerhard Weikum. ISWC 2018
[3] Coverage of Information Extraction from Sentences and Paragraphs. Simon Razniewski, Nitisha Jain, Paramita Mirza, Gerhard Weikum. EMNLP 2019

Simon Razniewski
DEPT. 5 Databases and Information Systems
Phone +49.681.9325-5126
Email: srazniew@mpi-inf.mpg.de