3D Object Detection
Bojan Pepik & Michael Stark
3D Object Detection
Detecting and localizing objects in images and videos is a key component of many applications in robotics, autonomous driving, image search, and surveillance. Traditionally, the object detection task has been defined as the localization of instances of a certain object class (such as cars) in an image. That is, the input to an object class detector is an image, and the output is a two-dimensional bounding box that highlights the position of the detected object.
Recent work is making it increasingly clear that high-level applications like scene understanding and object tracking would benefit from a richer, three-dimensional object representation. Such a representation comprises, in addition to the traditional 2D bounding box, an estimate of the viewpoint under which an object is imaged as well as the relative 3D positions of object parts. It allows us to derive scene-level constraints between multiple objects in a scene (objects cannot overlap in 3D) and between multiple views of the same object (the viewpoints of different detections must be consistent with camera movement).
Similarly, the traditional focus on basic-level categories, such as cars, birds, and people, has been extended to finergrained categories, such as specific car brands or plant and animal species, again providing richer constraints for scenelevel reasoning.
3D deformable part-based models
The goal of this project has been to build a 3D object class detector that, along with a traditional 2D bounding box (Figure 1), provides an estimate of object viewpoints as well as relative 3D part positions (Figure 2).

Figure 1
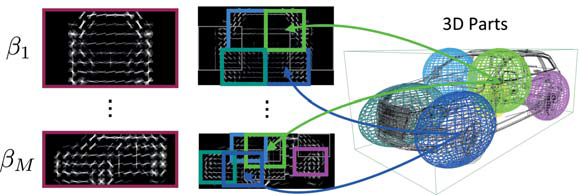
Figure 2
Since 3D object modeling requires supervision in the form of 3D data, we leverage 3D Computer Aided Design (CAD) models as a 3D geometry proxy for the object class of interest. In addition, we use 2D real-world imagery to obtain realistic appearance models. One of the main challenges consists in bridging the gap between artifi cial 3D geometry and 2D real-world appearance, which we achieve through a shape-based abstraction of object appearance based on non-photorealistic rendering. The fi nal 3D object class representation is then given by a probabilistic, part-based model, trained from both 3D and 2D data.
In our experiments, we have been able to demonstrate excellent performance in both the traditional 2D bounding box localization task and tasks aimed at scene-level reasoning, such as viewpoint estimation and ultra-wide baseline matching.
Occlusion patterns for object class detection
In this project, we have focused on improving object class detection in the face of partial occlusion, as it occurs when the view onto an object is blocked by other objects. This situation can be frequently observed, for example, in street scenes, where cars block the view onto other cars. Our approach is based on the intuition that the resulting occlusions often follow similar patterns that can be exploited, such as cars parked in front of other cars at the side of the road.
We have extended our 3D object class representation to include occlusion patterns in the form of object pairs. In our experiments, we have shown that our model outperforms prior work in both 2D object class detection and viewpoint estimation.
Bojan Pepik

DEPT. 2 Computer Vision and Multimodal Computing
Phone +49 681 9325-2108
Email bojan@mpi-inf.mpg.de
Michael Stark

DEPT. 2 Computer Vision and Multimodal Computing
Phone +49 681 9325-2120
Email stark@mi-inf.mpg.de