LM4KBC
Knowledge Base Completion for Long-Tail Entities
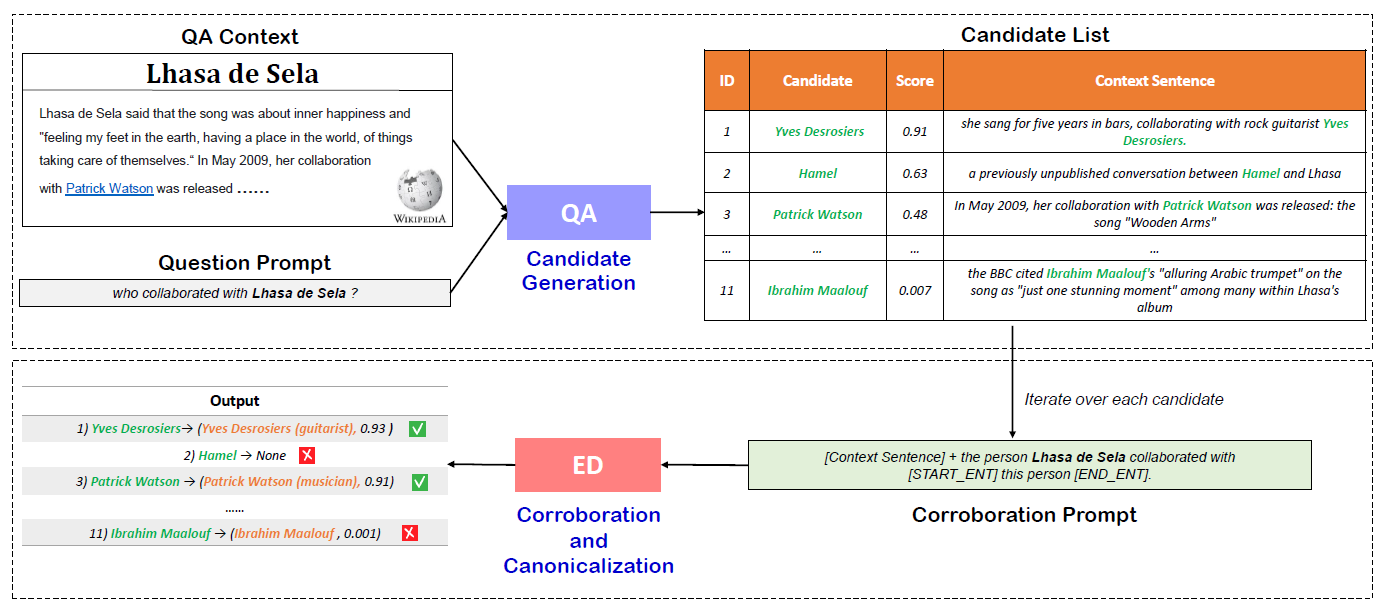
In this paper, we propose an unsupervised framework for knowledge base completion and a new dataset named MALT for evaluation. The main benefits of our approach are:
- fully prompt-based. To extract a new relation, the only thing needed in this framework is to design a prompt.
- can deal with multi-token and ambiguous entities
- work well on long-tail entities
Our method employs two different LMs in a two-stage pipeline as shown in the above Figure. The first stage generates candidate answers to input prompts and gives cues to retrieve informative sentences from Wikipedia and other sources. The second stage validates the candidates and disambiguates the retained answer strings onto entities in the underlying KG (e.g., mapping “Yves Desrosiers” to Yves Desrosiers (guitarist)).
Usage
The repo structure is shown below. The two_stage_pipeline.py file is the code of our two-stage framework, the GENRE path is a submodule that for the corroboration step, and the data path contains the MALT dataset
ROOT:.
¦ candidate_generation.py
¦ corroboration.py
¦ evaluate.py
¦ LICENSE
¦ README.md
¦ template.py
¦ two_stage_pipeline.py
¦ utils.py
¦
+---GENRE
¦
+---data
¦ entity_name_qid.txt
¦ gold_wikidata.json
¦ malt_eval.txt
¦ malt_hold_out.txt
¦ wikipedia.json
¦
+---figure
¦ framework.png
¦ malt.png
¦ prompt.png
¦ Data Preparation
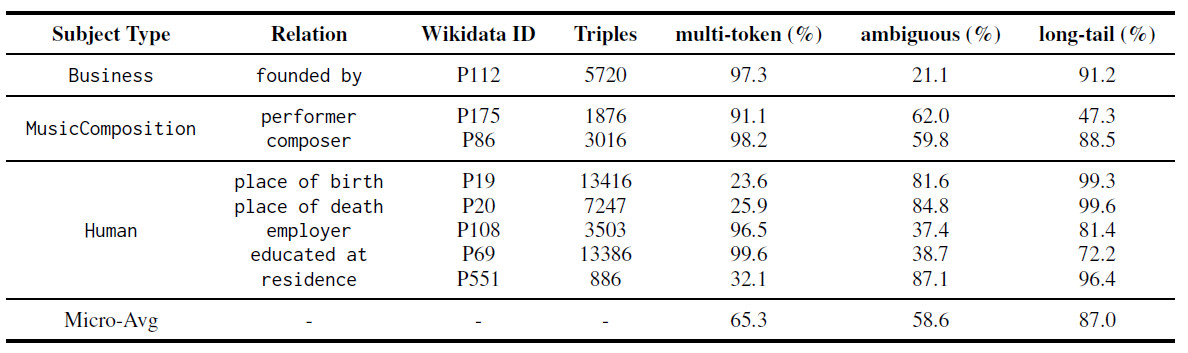
We developed a new dataset with an emphasis on the long-tail challenge, called MALT (for “Multi-token, Ambiguous, Long-Tailed facts”). After downloading, put the MALT file in the root path. There are five files in the MALT dataset:
malt_eval.txtcontains entity IDs for evaluationmalt_hold_out.txtcontains entity IDs for adjusting the hyper-parametersgold_wikidata.jsoncontains the gold factswikipedia.jsoncontains the corresponding Wikipedia pagesentity_name_qid.txt
The below table shows the stats of the MALT dataset, which contains many multi-token, ambiguous, and long-tail facts.
Run Example
Given the input document:
Lhasa de Sela said that the song was about inner happiness and "feeling my feet in the earth, having a place in the world, of things taking care of themselves.“ In May 2009, her collaboration with Patrick Watson was released.
We'd like to extract the collaborators for the singer "Lhasa de Sela".
python two_stage_pipeline.py -run_example True
After, the output is shown below:
( Lhasa de Sela, collaborator, Patrick Watson, 0.4763992584808626 )
( Lhasa de Sela, collaborator, Patrick Watson (musician), 0.3224404241174992 )
( Lhasa de Sela, collaborator, Patrick Watson (producer), 0.2401321410226018 )
Run MALT
python two_stage_pipeline.py -run_example False
After, you can get two files:
extracted_facts.txtstores the facts extracted by our frameworkscore.txtstores the evaluation scores (precision, recall, and f1)
Acknowledgements
This work was partially funded by ANR-20-CHIA0012-01 (“NoRDF”).
License
The MALT dataset is licensed under CC BY-SA 4.0 and the code is licensed under the MIT license