Implementation
For an in-depth look on Waldmeister, see "CITIUS, ALTIUS, FORTIUS: Lessons learned from the Theorem Prover Waldmeister".
Introduction
Waldmeister is a theorem prover for first order unit equational logic. It is based on unfailing Knuth-Bendix completion employed as proof procedure. Waldmeister's main advantage is that efficiency has been reached in terms of time as well as of space.
In outline, the task Waldmeister deals with is the following: A theory is formulated as a set E f implicitly universally quantified equationsover a many-sorted signature. It shall be demonstrated that a given equation s=t is valid in this equational theory, i.e. that it holds in all models of E. Equivalently, s is deducible from t by applications of the axioms of E, substiyuting equals for equals. - In 1970, Knuth and Bendix presented a completion algorithm, which later was extended to unfailing completion, as described e.g. by Bachmair et al. Parameterized with a reduction ordering, the unfailing varinat transforms E into a ground convergent set of rewrite rules. For theoretical reasons, this set is not necessarily finite, but if so, the word problem of E is solved by testing for syntactical identity after normalization. In both cases, however, if s=t holds, then a proff is always found in finite time. This justifies the use of unfailing completion as semi-complete proof procedure for equational logic.
Accordingly, when searching for a proof, Waldmeister saturates the given axiomatization until the goals can be shown by narrowing or rewriting. The saturation is performed in a cycle working on a set of waiting facts (critical pairs) and a set of selected facts (rules). Inside the completion loop, the following steps are performed:
1. Select an equation from the set of critical pairs.
2. Simplify this equation to a normal form. Discard if trivial, otherwise orient if possible.
3. Modify the set of rules according to the equation.
4. Generate all new critical pairs.
5. Add the equation to the set of rules.
The selection is controlled by a top-level heuristic maintaining a priority queue on the critical pairs. This top-level heuristic is one of the two most important control parameters. The other one is the reduction ordering to orient rules with. There is some evidence that the latter is of even stronger influence.
Unfailing Knuth Bendix completion (excerpt from the <a href="https://www.mpi-inf.mpg.de/departments/automation-of-logic/software/waldmeister/references/">SEKI Report</a>)
What is the typical task of a deduction system? A fixed logic has been operationalized towards a calculus the application of which is steered by some control strategy. Before we will describe the implementation of Waldmeister, we will state the starting point of the whole process, i.e. the inference system for
unfailing Knuth-Bendix completion.
Unfailing completion
In a paper that was published 1970, Knuth and Bendix introduced the completion algorithm which tries to derive a set of convergent rules from a given set of equations. With the extension to unfailing completion in a later paper by Bachmair, Dershowitz and Plaisted, it has turned out to be a valuable means of proving theorems in equational theories.
The following nine inference rules form a variant of unfailing completion which is suitable for equational reasoning.
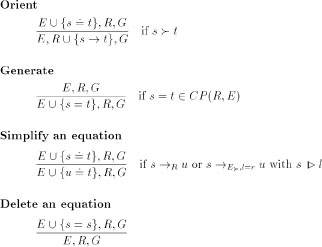

An informal illustration of the inference system is given here. The boxes represent sets in the mathematical sense and contain pairs of terms: namely rules, equations, goals, and critical pairs.
Initially, E includes the axioms and G the hypotheses. The set CP(R,E) is a function of the current sets R and E and holds the essence of all the local divergencies.
These arise whenever on the same term two different rewrite steps are applicable.
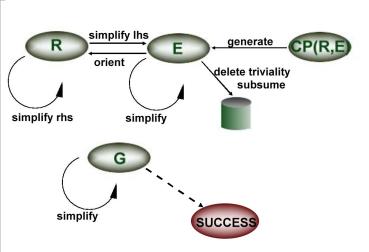
An informal illustration of the inference system is given here. The boxes represent sets in the mathematical sense and contain pairs of terms: namely rules, equations, goals, and critical pairs.
Initially, E includes the axioms and G the hypotheses. The set CP(R,E) is a function of the current sets R and E and holds the essence of all the local divergencies.
These arise whenever on the same term two different rewrite steps are applicable.
The arrows denote single inference steps, and each shifts a single termpair from one set to another. Along the simplify arrows, the terms alter according to the single-step rewrite relation induced by R and E. An equation with identical sides may be deleted. The same applies to an equation that is subsumed by a more general one. As soon as one side is greater than the other with respect to a fixed reduction ordering, the equation may be oriented into a rule. If the left-hand side of a rule is simplified, this rule becomes an equation again. This does not happen when reducing the right-hand side. A new equation is generated by selecting a termpair from CP(R,E). As soon as left-hand side and right-hand side of a goal are identical, the
corresponding hypothesis is successfully proved.
Instantiating this inference system leads to proof procedures. To achieve semi-completeness, a control constraint - the so-called fairness - has to be considered: From every critical pair the parents of which are persistent an equation must be generated some time.
Implementation
In the making of Waldmeister, we have applied an engineering approach, identifying the critical points leading to efficiency. We have started from a three-level system model consisting of inference step execution, aggregation into an inference machine, and topping search strategy. See our SEKI-Report for a detailed description of the entire design process.
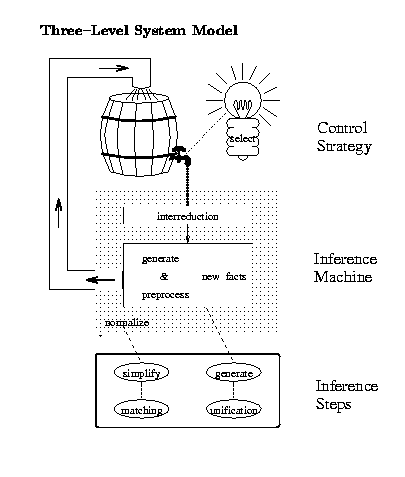
The main completion loop is parameterized by a selection heuristic and a reduction ordering. Both are derived from the algebraic structure described by the axioms.
The derivation process has been lifted such that control knowledge is expressed declaratively, which eases the integration of human experience.
For full flexibility, the search parameters may be re-instantiated during the proof search.
For the mid-level, flexible adjustment has proven essential as experimental evaluation has shown.
On the lowest level, we put great stress on efficiency in terms of time and space. To that purpose, we employ special indexing techniques and space-saving representations along with a specialized memory management.
The main goal during the development of Waldmeister was overall efficiency. To achieve this goal, one has to follow the paradigm of an engineering approach: Analyzing typical saturation-based provers, we recognize a logical three-level structure. We will analyze each of these levels with respect to the critical points responsible for the prover's overall performance. Wherever necessary, the question of how to tackle these critical points will have to be answered by extensive experimentation and statistical evaluation. In this context, an experiment is a fair, quantitative comparison of different realizations of the same functionality within the same system. Hence, modularity has to be a major principle in structuring the system.
Now, what does that mean in practice? Imagine a certain functionality needed for constructing say an unfailing completion procedure, e.g. normalization of terms. Out of the infinitely many different realizations, one could choose an arbitrary one and forget about the rest. However, there is no justification for restricting a system to a single normalization strategy, since different strategies are in demand for different domains. Hence, the system should include numerous normalization routines (allowing easy addition of other realizations) and leave the choice between them up to the user. As this applies to many choice points, an open system architecture produces a set of system parameters for fixing open choice points in one of the supported ways, and thus allows an easy experimental comparison of the different solutions. It is not before now that an optimal one can be named - if there is one: in some cases different domains require different solutions.
In this section we will depict the afore-mentioned three-level model, and describe the systematic stepwise design process we followed during the development of Waldmeister. The seven steps we have followed can be generalized towards applicability to arbitrary (synthetic) deduction systems.
The three-level model
We aim at automated deduction systems including a certain amount of control coping with many standard problems - in contrast to interactive provers. The basis for our development is the afore-mentioned logical three-level model of completion-based provers.
As every calculus that is given as an inference system, unfailing completion has many inherent indeterminisms. When realizing completion procedures in provers, this leads to a large family of deterministic, but parameterized algorithms. Two main parameters are typical for such provers: the reduction ordering as well as the search heuristic for guiding the proof. Choosing them for a given proof task forms the top level in our model.
The mid-level is that of the inference machine, which aggregates the inference rules of the proof calculus into the main completion loop. This loop is deterministic for any fixed choice of reduction ordering and selection heuristic. Since there is a large amount of freedom, many experiments are necessary to assess the differing aggregations before a generally useful one can be found. The lowest level provides efficient algorithms and sophisticated data structures for the execution of the most frequently used basic operations, e.g. matching, unification, storage and retrieval of facts. These operations consume most of the time and space.
Trying to solve a given problem by application of an inference system, one has to proceed as follows:
while the problem is not yet solved do
end |
Let us have a look at the inference system for unfailing completion:
Orienting an equation into a rule is instantiated with an equation and the given reduction ordering that is fixed during the proof run.
The four simplifying inference rules each have to be instantiated with the object, namely the equation, rule or goal they are applied to, the position in the term to be simplified and the rule or equation used for simplification.
The decision which equation should be deleted from the set E due to triviality or due to subsumption obviously is of minor importance. Nevertheless, as subsumption testing takes time, it should be possible to turn it off if the proof process does not benefit from it.
Finally, there is the generation of new equations which depends on the "parent'' rules / equations and a term position, restricted by the existence of a unifier.
Selection
Since selection can be seen as the search for the "best'' element in SUE, it is of the same complexity as a minimum-search. Taking a look at the changes that appear in SUE between two successive applications of select reveals that exactly one element has been removed whereas a few elements might have been added. As every selection strategy induces an ordering on this set, we can realize SUE as a priority queue.
Storing all the unselected but preprocessed equations in such a manner induces serious space problems. Hence, we follow two approaches to keep this set small. On the one hand, the total number of generated equations should be minimized. As only critical pairs built with rules and equations from R and Eselected will be added to SUE, we must guarantee that R and Eselected holds rules and equations which are minimal in the following sense: A rule or equation is minimal if each of the following conditions holds:
- both sides cannot be simplified by any other minimal rule or equation,
- it is not trivial and cannot be subsumed,
- it has not been considered superfluous by subconnectedness criteria,
- it has been assessed valuable and thus once been {\em selected}, and
- it has been oriented into a rule if possible.
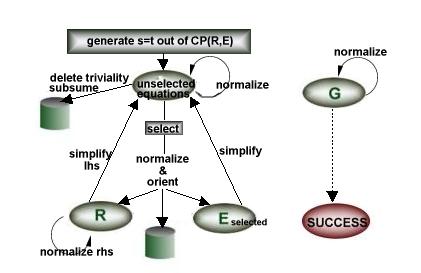
A newly selected equation will first be normalized (applying simplify), then deleted or subsumed if possible. Then the new member of R and Eselected is used to modify the facts already in R and Eselected (interreduction), or the critical pairs in SUE.
Afterwards, it will be added to R if it could be oriented, otherwise it becomes a member of Eselected.
Former rules or equations that have been removed during interreduction will be added to SUE again. Finally, all the critical pairs that can be built with the new rule or equation are generated, preprocessed, and added to SUE which closes the cycle.
From time to time, one must take a look at the goals and check whether they can already be joined.
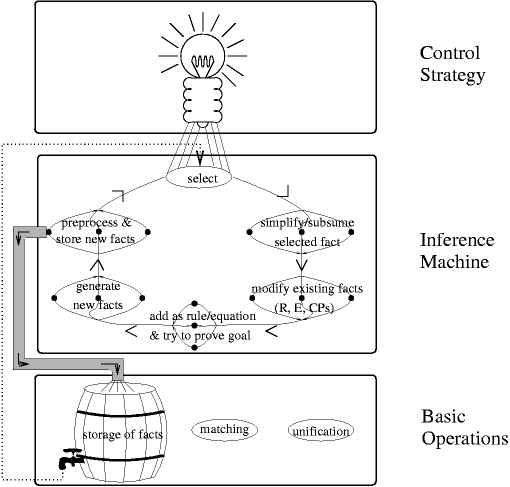
Furthermore, reprocessing the elements of SUE should be taken into consideration (intermediate reprocessing, IRP). We have instantiated the general three-level model according to this sketch of algorithm.
Define a set of system parameters determined by users
Having designed a sketch of algorithm, we now have to deal with those choice points which could not definitely be fixed by experience and thus - in the framework of an open system architecture as induced by the engineering approach - shall be left open to the user. More precisely, some of the system's functionality will have to be realized in different ways: A certain task will be fulfilled by several components; and the user (or the control strategy) must be able to select one of them at run time. This leads to a corresponding set of system parameters. As soon as the deduction system is completed, statistical evaluations of different parameter settings should result in a kind of default setting suitable for most problem classes.
In the context of unfailing completion, we found three groups of remaining choice points.
High-level control parameters:
the reduction ordering yielding oriented equality, and the select function guiding the selection of equations from SUE.
Treatment of unselected equations:
the organization of intermediate reprocessing which includes simplification and/or re-classification of the yet unselected equations, the criteria that shall be applied immediately after new equations have been generated (e.g. subconnectedness criteria), and the amount of simplification preceeding the classification of newly generated equations (preprocessing).
Normalization of terms:
the term traversal strategy (e.g. leftmost-outermost, leftmost-innermost), the way of combining R and Eselectedwhich may differ for the various situations normalization is applied, the priority of rules when simplifying with respect to R and Eselected, the question which of the possibly more than one applicable rules and / or equations shall be applied, and the backtracking behaviour after the execution of a single rewrite-step.
Although a few of these choice points might appear quite unimportant, all of them have proven valuable during our experimental analysis, or at least of significant influence on the prover's performance.
So Waldmeister allows the user to make a choice between diffrent options for the mentioned choice points. For more on this, see the Waldmeister documentation that comes with the Waldmeister distribution.