Personal Knowledge Base
Personal knowledge about users’ professions, hobbies, favorite food, and travel preferences, among others, is a valuable asset for individualized AI, such as recommenders or chatbots. In this line of research we explore the task of acquiring such knowledge from conversational utterances in order to build a Personal Knowledge Base (PKB) that is scrutable and explainable. This problem is more challenging than the established task of information extraction from scientific publications or Wikipedia articles, because dialogues or user-generated content in social media often give merely implicit cues about the user/speaker.
PRIDE: Predicting Relationships In Dialogue Excerpts
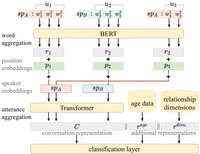
Automatically extracted interpersonal relationships of conversation interlocutors can enrich personal knowledge bases to enhance personalized search, recommenders and chatbots. To infer speakers' relationships from dialogues we propose PRIDE, a neural multi-label classifier, based on BERT and Transformer for creating a conversation representation. PRIDE utilizes the dialogue structure and augments it with external knowledge about speaker features and conversation style.
Unlike prior works, we address multi-label prediction of fine-grained relationships. We release large-scale datasets, based on screenplays of movies and TV shows, with directed relationships of conversation participants. Extensive experiments on both datasets show superior performance of PRIDE compared to the state-of-the-art baselines.
Publications
Anna Tigunova, Paramita Mirza, Andrew Yates and Gerhard Weikum. PRIDE: Predicting Relationships in Conversations. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP '21) (to appear).
Source code: https://github.com/Anna146/PRIDE
Downloads
We release datasets of fictional character pairs, taken from movies and TV series, labeled with their relationships:
- movie pairs: download, dialogs per character pair are taken from the movie scripts in the Scriptbase-J corpus.
- series pairs: download, dialogs per character pair are taken from our dataset of TV scripts.
Please refer to the README file for more details.
License (for files): Creative Commons Attribution 4.0 International (CC BY 4.0)
CHARM: Conversational Hidden Attribute Retrieval Model
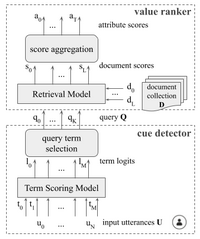
Prior work developed supervised methods to extract personal knowledge from conversational data, including users' utterances in social media, but these approaches can not generalize beyond attribute values with ample labeled training samples. We overcome this limitation by devising CHARM: a zero-shot learning method that creatively leverages keyword extraction and document retrieval in order to predict attribute values that were never seen during training. Experiments with large datasets from Reddit show the viability of CHARM for open-ended attributes, such as professions and hobbies.
Publications
Anna Tigunova, Andrew Yates, Paramita Mirza and Gerhard Weikum. CHARM: Conversational Hidden Attribute Retrieval Model. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP '20), pages 5391–5404. [pdf] [bib]
Anna Tigunova, Paramita Mirza, Andrew Yates and Gerhard Weikum. Exploring Personal Knowledge Extraction from Conversations with CHARM. In Proceedings of the 14th ACM International Conference on Web Search and Data Mining (WSDM '21), pages 1077–1080. [pdf]
Source code: https://github.com/Anna146/CHARM
Demo: https://d5demos.mpi-inf.mpg.de/charm/
HAM: Hidden Attribute Models
We propose methods for inferring personal knowledge, such as profession, age or family status, from conversations using deep learning. Specifically, we propose several Hidden Attribute Models, which are neural networks leveraging attention mechanisms and embeddings. Our methods are trained on a per-predicate basis to output rankings of object values for a given subject-predicate combination (e.g., ranking the doctor and nurse professions high when speakers talk about patients, emergency rooms, etc). Experiments with various conversational texts including Reddit discussions, movie scripts and a collection of crowdsourced personal dialogues demonstrate the viability of our methods and their superior performance compared to state-of-the-art baselines.
Publications
Anna Tigunova, Andrew Yates, Paramita Mirza and Gerhard Weikum. Listening between the Lines: Learning Personal Attributes from Conversations. In Proceedings of The Web Conference (WWW) 2019, pages 1818–1828, San Francisco, CA, United States. [pdf]
Source code and data: https://github.com/Anna146/HiddenAttributeModels
MovieChAtt dataset
Dataset of characters in popular movies labeled with profession, age and gender attributes.
RedDust: a Large Reusable Dataset of Reddit User Traits
Social media is a rich source of assertions about personal attributes, such as "I am a doctor" or "my hobby is playing tennis". Precisely identifying explicit assertions is difficult, though, because of the users’ highly varied vocabulary and language expressions. Identifying personal attributes from implicit assertions like "I've been at work treating patients all day" is even more challenging.
We present RedDust, a large-scale annotated resource for user profiling for over 300k Reddit users across five attributes: profession, hobby, family status, age, and gender. We construct RedDust using a diverse set of high-precision patterns and demonstrate its use as a resource for developing learning models to deal with implicit assertions. RedDust consists of users’ personal attribute labels, along with users’ post ids, which may be used to retrieve the posts from a publicly available crawl or from the Reddit API. To the best of our knowledge, RedDust is the first annotated language resource about Reddit users at large scale. We envision further use cases of RedDust for providing background knowledge about user traits, to enhance personalized search and recommendation as well as conversational agents.
Publications
Anna Tigunova, Andrew Yates, Paramita Mirza and Gerhard Weikum. RedDust: a Large Reusable Dataset of Reddit User Traits. In Proceedings of the 12th International Conference on Language Resources and Evaluation (LREC 2020). [pdf] [bib]
Downloads
RedDust contains labeled Reddit users with the following attributes:
To retrieve the text from the ids provided in the files, please use the pushift.io data dumps (https://files.pushshift.io/reddit/comments/, https://files.pushshift.io/reddit/submissions/). Note, that using Reddit API will not work to get the texts.
To access the RedDust dataset contact Anna (belpku001[at]mail[dot]ru).
Please refer to the README file for more details.
License (for files): Creative Commons Attribution 4.0 International (CC BY 4.0)