Quasimodo KB
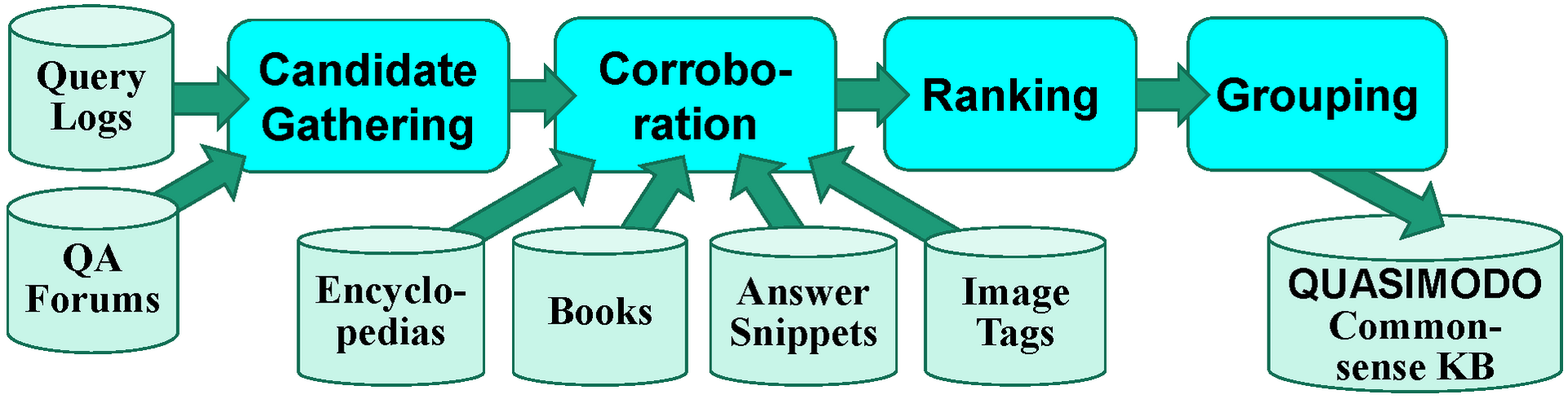
Commonsense knowledge about object properties, human behavior and general concepts is crucial for robust AI applications. However, automatic acquisition of this knowledge is challenging because of sparseness and bias in online sources. This paper presents Quasimodo, a methodology and tool suite for distilling commonsense properties from non-standard web sources. We devise novel ways of tapping into search-engine query logs and QA forums, and combining the resulting candidate assertions with statistical cues from encyclopedias, books and image tags in a corroboration step. Unlike prior work on commonsense knowledge bases, Quasimodo focuses on salient properties that are typically associated with certain objects or concepts. Extensive evaluations, including extrinsic use-case studies, show that Quasimodo provides better coverage than state-of-the-art baselines with comparable quality.
Publication
- Commonsense Properties from Query Logs and Question Answering Forums, Julien Romero, Simon Razniewski, Koninika Pal, Jeff Z. Pan, Archit Sakhadeo, Gerhard Weikum, CIKM 2019 [pdf]
- Inside Quasimodo: Exploring Construction and Usage of Commonsense Knowledge, Julien Romero and Simon Razniewski, CIKM 2020 [pdf][demo]
Data and Code
Web interface
Download v4.3
Format:
- subject: The subject of the triple
- predicate: The predicate of the triple
- object: The object of the triple
- modality: Modalities associated with the triples with their counts. TBC means the object can be further refined to the listed objects
- is_negative: 1 if the statement was negated
- score: salience score of the supervised scoring model
- neighborhood sigma: Relaxed uniqueness measure of a statement w.r.t. statements with a similar predicate and object for other subjects.
- local sigma: strict conditional probability of observing a (predicate, object) with a specific subject. I.e., a measure of how unique a statement is. E.g., local_sigma(lawyers, defend, serial_killers) = 1, local_sigma(lawyers, make, money) = 0.01, even though both statements have a similar score of 0.99.
Sample excerpts
Other subsets
- Positive statements only
- Negated statements only
- Occupations
- Animals
- Culture
- ConceptNet-mapped statements
Details on all these subsets are in the appendix of the Arxiv paper.
Older version
Additional fields in v1.2:
- tau_score: The typicality score
- sigma_score: The saliency score
Crowd statements for recall assessment:
Code
License
All data and code are released under CC-BY 2.0. Suggested citation format: "Romero et al., Commonsense Properties from Query Logs and Question Answering Forums, CIKM, 2019".