Visual Turing Challenge
Mateusz Malinowski and Mario Fritz
Challenge
As language and visual understanding by machines progresses rapidly, we are observing an increasing interest in holistic architectures that tightly interlink both modalities in a joint learning and inference process. This trend has allowed the community to progress towards more challenging and open-ended tasks and refueled the hope at achieving the old AI dream of building machines that could pass a turing test in open domains.
In this line of research, our primary focus lies on building machines that answer questions about images. Moreover, we also explore different ways of benchmarking the machines on this complex and ambiguous task. In [3] and [4], we provide a wider view on question answering based on images task. We enumerate the challenges that holistic learners have to face with, and discuss advantages of the question answering task over other high cognitive problems, most prominently scalable annotation effort and automatic benchmarking tools.
In [1], we propose a symbolic-based approach to answer questions about images, where we combine a 'soft' perception with a symbolic reasoning. Our Bayesian formulation extends the work on semantic parsing (P. Liang 'Learning dependency-based compositional semantics') to handle many interpretations of a scene as well. In addition, we also introduce a WUPS score as a 'softer' generalization of the Accuracy measure that handles with word-level ambiguities. In this work, we also propose DAQUAR - a dataset of human question answer pairs about images, which manifests our vision on a Visual Turing Test.
In [2], we propose a neural-based approach to answer questions about images that combines Convolutional Neural Network together with a Recurrent Neural Network (LSTM). It is an end-to-end, jointly trained, modular approach that liberates us from many design choices required in the previous work. The network has successfully learnt patterns that occur in language, significantly improving over the previous work. Moreover, we extend the WUPS scores to handle multiple interpretations of a question via Consensus, which also partitions the dataset according to difficulty/ambiguity of questions. Finally, we give further insights about both the problem and DAQUAR.
References
[1] A Multi-World Approach to Question Answering about Real-World Scenes based on Uncertain Input. M. Malinowski, and M. Fritz. NIPS 2014.
[2] Ask Your Neurons: A Neural-based Approach to Answering Questions about Images. M. Malinowski, M. Rohrbach, and M. Fritz. ICCV 2015, Oral. Supplementary Material. Spotlight.
[3] Towards a Visual Turing Challenge . M. Malinowski, and M. Fritz. NIPS 2014 Workshop on Learning Semantics.
[4] Hard to Cheat: A Turing Test based on Answering Questions about Images. M. Malinowski, and M. Fritz. AAAI 2015 Workshop on Beyond the Turing Test.
DAQUAR - DAtaset for QUestion Answering on Real-world images
- Full DAQUAR (all classes)
- Reduced DAQUAR (37 classes and 25 test images)
- Consensus data on DAQUAR
- Consensus - questions and answers
- hash '#' in answers denotes some problems in answering the question
- Consensus - questions and answers
- DAQUAR builds upon NYU Depth v2 by N. Silberman et.al.
- Metrics measuring performance
If you have further questions, please contact Mateusz Malinowski.
If you use our dataset, please cite our NIPS paper:
@INPROCEEDINGS{malinowski2014nips,
author = {Malinowski, Mateusz and Fritz, Mario},
title = {A Multi-World Approach to Question Answering about Real-World Scenes based on Uncertain Input},
booktitle = {Advances in Neural Information Processing Systems 27},
editor = {Z. Ghahramani and M. Welling and C. Cortes and N.D. Lawrence and K.Q. Weinberger},
pages = {1682--1690},
year = {2014},
publisher = {Curran Associates, Inc.},
url = {http://papers.nips.cc/paper/5411-a-multi-world-approach-to-question-answering-about-real-world-scenes-based-on-uncertain-input.pdf}
}Challenges in DAQUAR

Figure 1. Concepts ambiguity, changes of the frame of reference and human notion of spatial relations are dominant challenges in DAQUAR.



")
Slides
 Slides")

Methods
A neural approach to Visual Turing Test (ICCV'15)
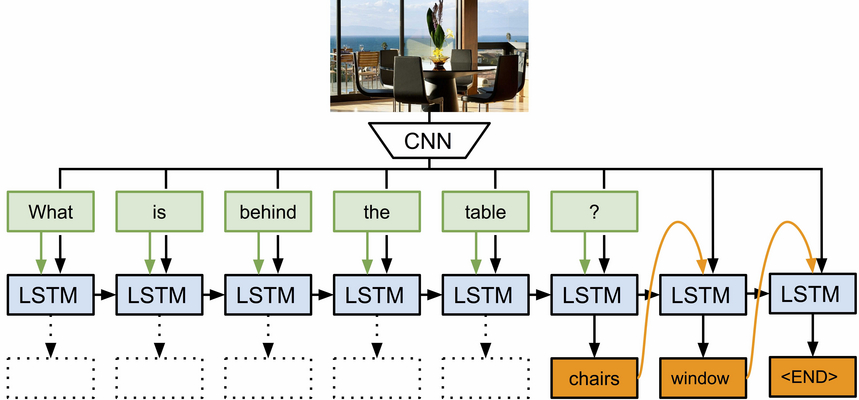
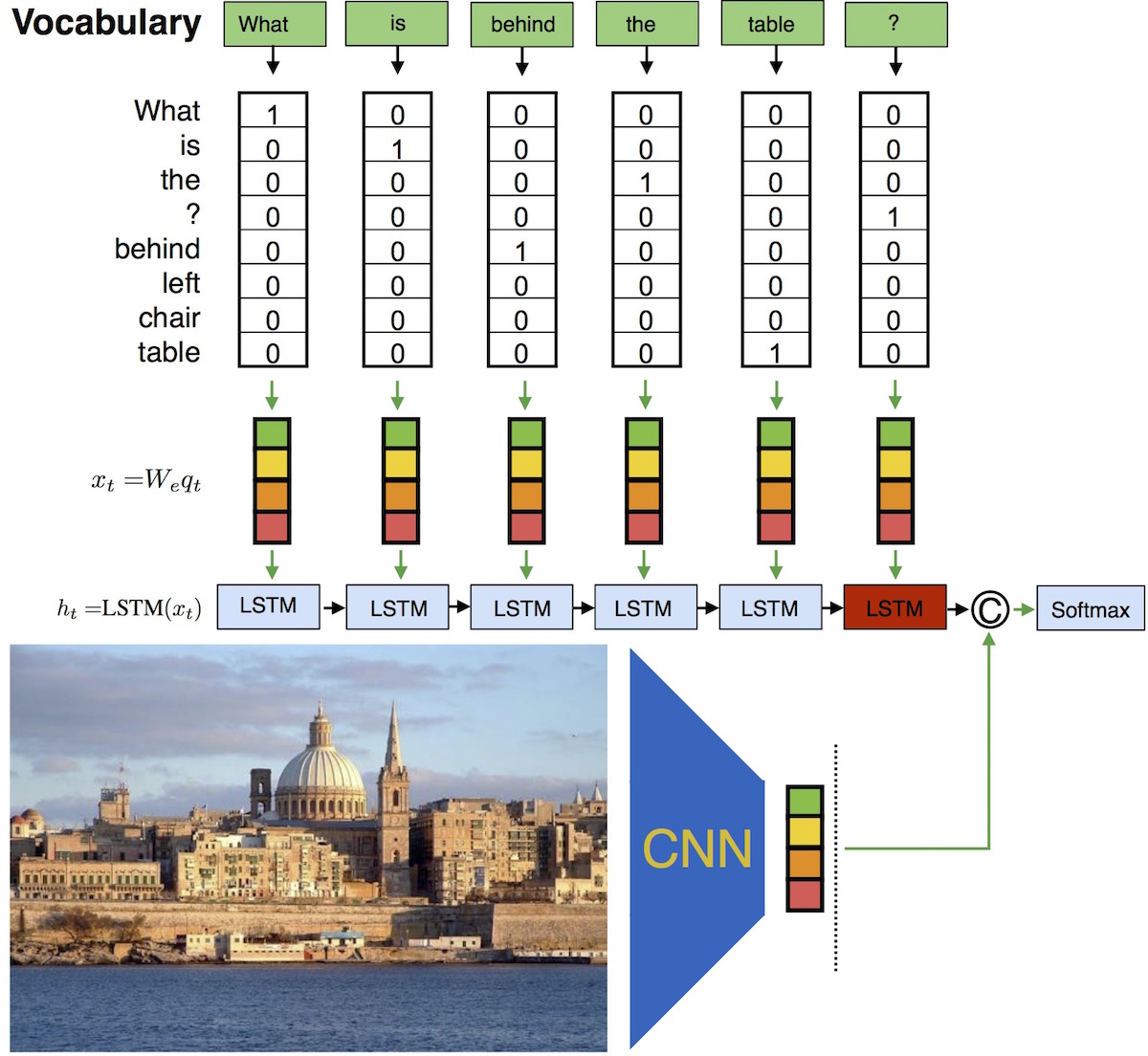
Figure 2. Our approach Neural-Image-QA to question answering with a Recurrent Neural Network using Long Short Term Memory (LSTM). To answer a question about an image, we feed in both, the image (CNN features) and the question (green boxes) into the LSTM. After the (variable length) question is encoded, we generate the answers (multiple words, orange boxes). During the answer generation phase the previously predicted answer words are fed into the LSTM until the <END> symbol is predicted.
A symbolic approach to Visual Turing Test (NIPS'14)
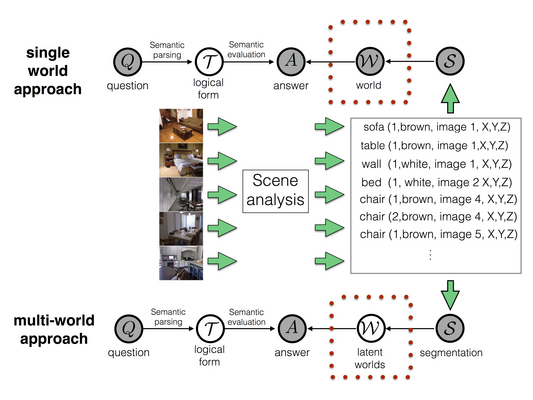
Figure 3. Overview of our approach to question answering task. A state-of-the-art scene segmentation method divides images into semantic segments that are represented as predicates. This step creates a set of visual facts that are used by semantic parser to retrieve an answer for a given question. The single world approach averages only over multiple interpretations of a question and considers a unique scene interpretation while our multi-world approach takes also multiple interpretations of a scene into account.
Results
| Setting | Method | Accuracy | WUPS at 0.9 | WUPS at 0.0 |
|---|---|---|---|---|
| all classes | Human Baseline [1] | 50.20% | 50.82% | 67.27% |
| all classes | HumanSeg, Single-World [1] | 7.86% | 11.86% | 38.79% |
| all classes | Neural Image QA [2] | 19.43% | 25.28% | 62.00% |
| 37 classes | Human Baseline [1] | 60.27% | 61.04% | 78.96% |
| 37 classes | HumanSeg, Single-World [1] | 12.47% | 16.49% | 50.28% |
| 37 classes | AutoSeg, Multi-World [1] | 12.73% | 18.10% | 51.47% |
NEW: Code and Data for "Ask Your Neurons: A Neural-based Approach to Answering Questions about Images" (ICCV'15)
Required data to reproduce results of the multiple words model on the Full DAQUAR from the "Ask Your Neurons: A Neural-based Approach to Answering Questions about Images" paper.
- Berkeley LRCN
- In the experiments I use dev branch with the hashtag: 716262a87f16093af6a76afc3b176d15a963147c
- Data that contain
- DAQUAR dataset converted into HDF5 format (data/daquar/h5_data/)
- Snapshot with weights of trained model (data/daquar/snapshots/)
- ImageNet mean (data/imagenet/)
Code and Data for "A Multi-World Approach to Question Answering about Real-World Scenes based on Uncertain Input" (NIPS'14)
The following (exemplar) source files are compatible with the DCS Parser (Percy Liang et. al.), and are required to reproduce results from the " A Multi-World Approach to Question Answering about Real-World Scenes based on Uncertain Input" paper.
- Question answer pairs
- Question answer pairs - train/test split
- Lexicon
- Relations and facts
- relations.dlog
- facts (human segmentations, all classes), vocabulary, and schema
- colors relations
- facts for the reduced DAQUAR (37 classes)
- Reduced test set
The whole package compatible with the DCS Parser (Percy Liang et. al.) is used to train our system. In all packages we maintain the same structure as the DCS Parser source code.
- Instruction on the usage of the package
- Human segmentations, all classes
- Human segmentations, 37 classes, 25 test images
- Most confident world, 37 classes, 25 test images
- Multi-world approach, 37 classes, 25 test images (Coming Soon)
Statistics about DAQUAR
| number of questions: 12 468 |
| number of different questions: 2 483 [1] |
| average number of words in questions: 11.53 |
| the shortest question: 7 words |
| the longest question: 31 words |
| most answers have 1 entity |
| the longest answers have 7 entities |
| number of different nouns in questions: 803 |
| number of question answer pairs per image (trimean): 8.75 |
| number of the same object occurrences (trimean): 5.75 |
| number of the same object occurrences (mean): 22.48 |
| the most frequent answer object: table (469 occurrences) |
| the 2nd most frequent answer object: chair (412 occurrences) |
| the 3rd most frequent answer object: lamp (350 occurrences) |
| the most frequent answer number: 2 (554 occurrences) |
| the 2nd most frequent answer number: 3 (327) |
| the 3rd most frequent answer number: 1 (252) |
[1] To estimate this number, we remove image ids, all articles and nouns (we use a Stanford POS Tagger), and count how often such modified questions occur in the dataset.