Speaking the Same Language: Matching Machine to Human Captions by Adversarial Training
Rakshith Shetty, Marcus Rohrbach, Lisa Anne Hendricks, Mario Fritz and Bernt Schiele
Paper , Supplementary Material, Code
While strong progress has been made in image captioning recently, machine and human captions are still quite distinct. This is primarily due to the deficiencies in the generated word distribution, vocabulary size, and strong bias in the generators towards frequent captions. Furthermore, humans -- rightfully so -- generate multiple, diverse captions, due to the inherent ambiguity in the captioning task which is not explicitly considered in today's systems.
To address these challenges, we change the training objective of the caption generator from reproducing ground-truth captions to generating a set of captions that is indistinguishable from human written captions. Instead of handcrafting such a learning target, we employ adversarial training in combination with an approximate Gumbel sampler to implicitly match the generated distribution to the human one.
While our method achieves comparable performance to the state-of-the-art in terms of the correctness of the captions, we generate a set of diverse captions that are significantly less biased and better match the global uni-, bi- and tri-gram distributions of the human captions.


Caption generator model. Deep visual features are input to an LSTM to generate a sentence. A Gumbel sampler is used to obtain soft samples from the softmax distribution, allowing for backpropagation through the samples.

Discriminator Network. Caption set sampled from the generator is used to compute image to sentence and sentence-to-sentence distances. They are used to score the set as real/fake.
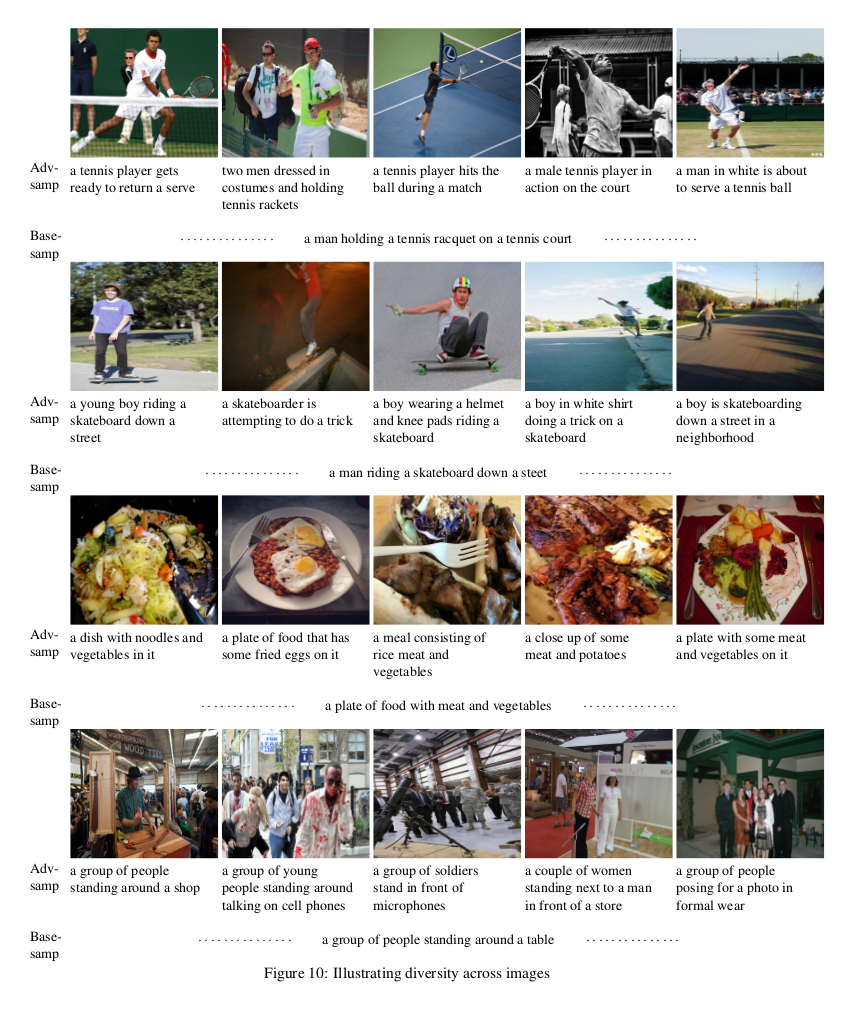
Examples illustrating Diversity

@inproceedings{ Shetty2017iccv,
title = {Speaking the Same Language: Matching Machine to Human Captions by Adversarial Training},
author = {Shetty, Rakshith and Rohrbach, Marcus and Hendricks, Lisa Anne and Fritz, Mario and Schiele, Bernt},
year = {2017},
journal = {Proceedings of the IEEE International Conference on Computer Vision (ICCV)} }