Weakly Supervised Learning
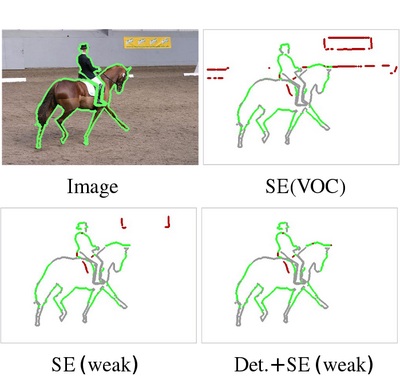
Weakly Supervised Object Boundaries
State-of-the-art learning based boundary detection methods require extensive training data. Since labelling object boundaries is one of the most expensive types of annotations, there is a need to relax the requirement to carefully annotate images to make both the training more affordable and to extend the amount of training data. In this paper we propose a technique to generate weakly supervised annotations and show that bounding box annotations alone suffice to reach high-quality object boundaries withoutusing any object-specific boundary annotations. With the proposed weak supervision techniques we achieve the top performance on the object boundary detection task, outperforming by a large margin the current fully supervised state-of-the-art methods.

Simple does it: Weakly Supervised Instance and Semantic Segmentation
Semantic labelling and instance segmentation are two tasks that require particularly costly annotations. Starting from weak supervision in the form of bounding box detection annotations, we propose a new approach that does not require modification of the segmentation training procedure. We show that when carefully designing the input labels from given bounding boxes, even a single round of training is enough to improve over previously reported weakly supervised results. Overall, our weak supervision approach reaches ~95% of the quality of the fully supervised model, both for semantic labelling and instance segmentation.

Exploiting Saliency for Object Segmentation from Image Level Labels
There have been remarkable improvements in the semantic labelling task in the recent years. However, the state of the art methods rely on large-scale pixel-level annotations. This paper studies the problem of training a pixel-wise semantic labeller network from image-level annotations of the present object classes. Recently, it has been shown that high quality seeds indicating discriminative object regions can be obtained from image-level labels. Without additional information, obtaining the full extent of the object is an inherently ill-posed problem due to co-occurrences. We propose using a saliency model as additional information and hereby exploit prior knowledge on the object extent and image statistics. We show how to combine both information sources in order to recover 80% of the fully supervised performance - which is the new state of the art in weakly supervised training for pixel-wise semantic labelling.
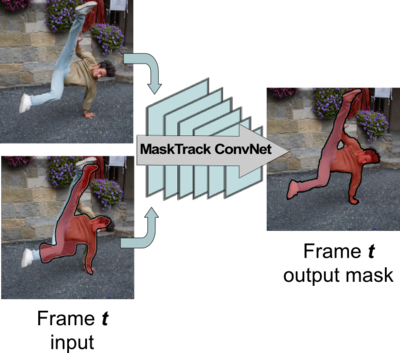
Learning Video Object Segmentation from Static Images
Inspired by recent advances of deep learning in instance segmentation and object tracking, we introduce video object segmentation problem as a concept of guided instance segmentation. Our model proceeds on a per-frame basis, guided by the output of the previous frame towards the object of interest in the next frame. We demonstrate that highly accurate object segmentation in videos can be enabled by using a convnet trained with static images only. The key ingredient of our approach is a combination of offline and online learning strategies, where the former serves to produce a refined mask from the previous’ frame estimate and the latter allows to capture the appearance of the specific object instance. Our method can handle different types of input annotations: bounding boxes and segments, as well as incorporate multiple annotated frames, making the system suitable for diverse applications. We obtain competitive results on three different datasets, independently from the type of input annotation.
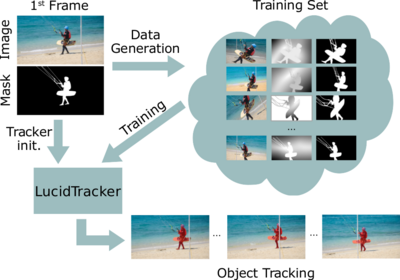
Lucid Data Dreaming for Object Tracking
Convolutional networks reach top quality in pixel-level object tracking but require a large amount of training data (1k ∼10k) to deliver such results. We propose a new training strategy which achieves state-of-the-art results while using 20×∼100× less annotated data than competing methods. Instead of using large training sets hoping to generalize across domains, we generate in-domain training data using the provided annotation on the first frame of each video to synthesize (“lucid dream” ) plausible future video frames. In-domain per-video training data allows us to train high quality appearance- and motion-based models, as well as tune the post-processing stage. This approach allows to reach competitive results even when training from only a single annotated frame, without ImageNet pre-training. Our results indicate that using a larger training set is not automatically better, and that for the tracking task a smaller training set that is closer to the target domain is more effective.