Vision and Language

Xplore-M-Ego: Contextual Media Retrieval Using Natural Language Queries
The widespread integration of cameras in hand-held and head-worn devices as well as the ability to share content online enables a large and diverse visual capture of the world. We envision these images and associated meta information to form a collective visual memory that can be queried while automatically taking the ever-changing context of mobile users into account. In this work we present Xplore-M-Ego: a novel media retrieval system that allows users to query a database of contextualised images using spatio-temporal natural language queries.

Visual Turing Challenge
As language and visual understanding by machines progresses rapidly, we are observing an increasing interest in holistic architectures that tightly interlink both modalities in a joint learning and inference process. This trend has allowed the community to progress towards more challenging and open-ended tasks and refueled the hope at achieving the old AI dream of building machines that could pass a turing test in open domains. In this project we propose a method for automatically answering questions about images and a challenging dataset of textual question answering pairs. Finally, we establish a first benchmark for this task that can be seen as a modern attempt at a visual turing test.
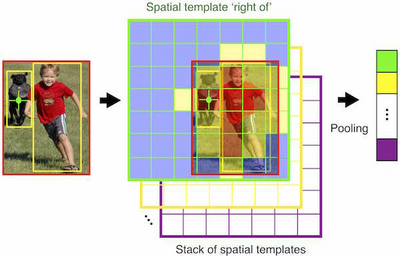
Learning Spatial Relations
In this project, we propose a pooling interpretation of spatial relations and show how it improves image retrieval and annotations tasks involving spatial language. Due to the complexity of the spatial language, we argue for a learning-based approach that acquires a representation of spatial relations by learning parameters of the pooling operator. We show improvements on previous work on two datasets and two different tasks as well as provide additional insights on a new dataset with an explicit focus on spatial relations.

TACoS Multi-Level Corpus
Existing approaches for automatic video description focus on generating single sentences at a single level of detail. We address both of these limitations: for a variable level of detail we produce coherent multi-sentence descriptions of complex videos featuring cooking activities. To understand the difference between detailed and short descriptions, we collect and analyze a video description corpus with three levels of detail.
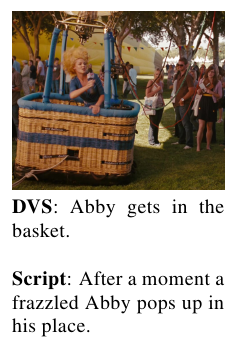
Movie Description Dataset
To foster the research on automatic video description we propose a new Movie Description Dataset, featuring movie snippets aligned to scripts and DVS (Descriptive video service). DVS is a linguistic description that allows visually impaired people to follow a movie. We benchmark state-of-the-art computer vision algorithms to recognize scenes, human activities, and participating objects and achieve encouraging results in video description on this new challenging dataset.
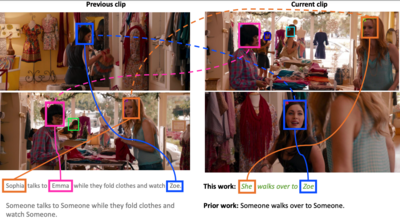
Grounded and Co-Referenced Characters
In this work we propose a movie description model which learns to generate description and jointly ground (localize) the mentioned characters as well as do visual co-reference resolution between pairs of consecutive sentences/clips. The web page provides access to the Dataset for Grounded and Co-Referenced Characters.