Video Segmentation

VSB100: A Unified Video Segmentation Benchmark
Video segmentation research is currently limited by the lack of a benchmark dataset that covers the large variety of subproblems appearing in video segmentation and that is large enough to avoid overfitting. Consequently, there is little analysis of video segmentation which generalizes across subtasks, and it is not yet clear which and how video segmentation should leverage the information from the still-frames, as previously studied in image segmentation, alongside video specific information, such as temporal volume, motion and occlusion. In this work we provide such an analysis based on annotations of a large video dataset, where each video is manually segmented by multiple persons. Moreover, we introduce a new volume-based metric that includes the important aspect of temporal consistency, that can deal with segmentation hierarchies, and that reflects the tradeoff between over-segmentation and segmentation accuracy.

Video Segmentation with Superpixels
This work contributes a thorough analysis of various within- and between-frame affinities suitable for video segmentation with superpixels. Additionally this work extends a state-of-the-art hierarchical image segmentation algorithm to include motion-cues, for the extraction of superpixels. The provided source code includes per-pixel-error benchmark metrics and the established image segmentation metrics of SC, PRI and VI computed on video volumes.

Learning Must-Link Constraints for Video Segmentation
Clustering and segmentation methods can greatly benefit from the integration of prior information in terms of must-link constraints. The use of such constraints has been integrated in a rigorous manner also in graph-based methods such as normalized cut. On the other hand spectral clustering as relaxation of the normalized cut has been shown to be among the best methods for video segmentation. We merge these two developments and propose to learn must-link constraints for video segmentation with spectral clustering.
Spectral graph reduction
Computational and memory costs restrict spectral techniques to rather small graphs, which is a serious limitation especially in video segmentation. In this work, we propose the use of a reduced graph based on superpixels. In contrast to previous work, the reduced graph is reweighted such that the resulting segmentation is equivalent, under certain assumptions, to that of the full graph. We consider equivalence in terms of the normalized cut and of its spectral clustering relaxation. The proposed method reduces runtime and memory consumption and yields on par results in image and video segmentation. Further, it enables an efficient data representation and update for a new streaming video segmentation approach that also achieves state-of-the-art performance.
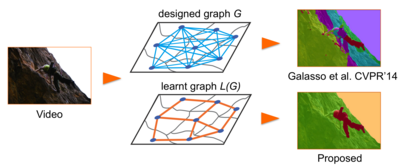
Classifier Based Graph Construction for Video Segmentation
In this project we address the classifier based graph construction procedure for video segmentation. We propose an empirical approach to learn both the edge topology and weights of the graph. While combining well-established features by means of a classifier and calibrating the classifier scores by its accuracy we alter the graph structure selecting the most confident edges. Our method of learning
the graph helps to improve both performance on the challenging VSB100 benchmark as well as efficiency without changing the graph partitioning model.

Improved Image Boundaries for Better Video Segmentation
Graph-based video segmentation methods rely on superpixels as starting point. While most previous work has focused on the construction of the graph edges and weights as well as solving the graph partitioning problem, this paper focuses on better superpixels for video segmentation. We demonstrate by a comparative analysis that superpixels extracted from boundaries perform best, and show that
boundary estimation can be significantly improved via image and time domain cues. With superpixels generated from our better boundaries we observe consistent improvement for two video segmentation methods in two different datasets.
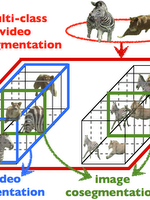
Multi-Class Video Co-Segmentation
In this project we propose to study multi-class video co-segmentation where the number of object classes is unknown as well as the number of instances in each frame and video. We achieve this by formulating a non-parametric bayesian model across videos sequences that is based on a new videos segmentation prior as well as a global appearance model that links segments of the same class.
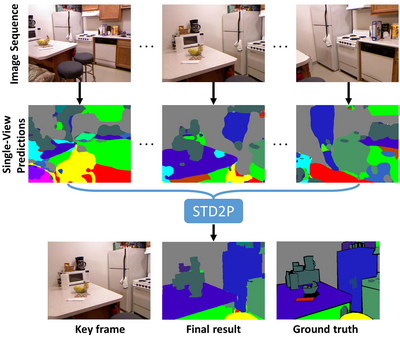
Semantic Image Segmentation from Videos
In this project, we propose a novel superpixel-based multi-view convolutional neural network for semantic image segmentation. The proposed network produces a high quality segmentation of a single image by leveraging information from additional views of the same scene. We first compute region correspondences by optical flow and image boundary-based superpixels. Given these region correspondences, we propose a novel spatio-temporal pooling layer to aggregate information over space and time. Besides a general improvement over the state-of-the-art, we also show the benefits of making use of unlabeled frames during training for multi-view as well as single-view prediction.
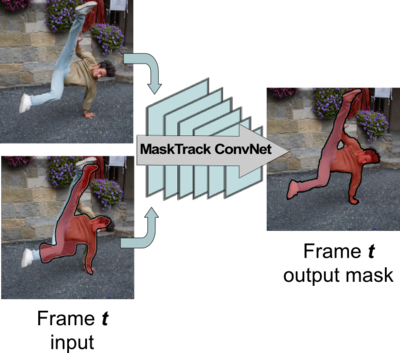
Learning Video Object Segmentation from Static Images
Inspired by recent advances of deep learning in instance segmentation and object tracking, we introduce video object segmentation problem as a concept of guided instance segmentation. Our model proceeds on a per-frame basis, guided by the output of the previous frame towards the object of interest in the next frame. We demonstrate that highly accurate object segmentation in videos can be enabled by using a convnet trained with static images only. The key ingredient of our approach is a combination of offline and online learning strategies, where the former serves to produce a refined mask from the previous’ frame estimate and the latter allows to capture the appearance of the specific object instance. Our method can handle different types of input annotations: bounding boxes and segments, as well as incorporate multiple annotated frames, making the system suitable for diverse applications. We obtain competitive results on three different datasets, independently from the type of input annotation.
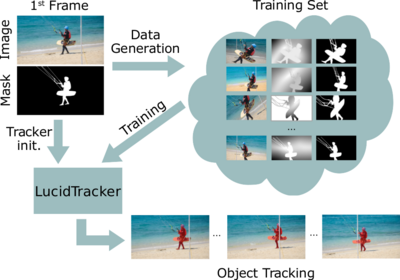
Lucid Data Dreaming for Object Tracking
Convolutional networks reach top quality in pixel-level object tracking but require a large amount of training data (1k ∼10k) to deliver such results. We propose a new training strategy which achieves state-of-the-art results while using 20×∼100× less annotated data than competing methods. Instead of using large training sets hoping to generalize across domains, we generate in-domain training data using the provided annotation on the first frame of each video to synthesize (“lucid dream” ) plausible future video frames. In-domain per-video training data allows us to train high quality appearance- and motion-based models, as well as tune the post-processing stage. This approach allows to reach competitive results even when training from only a single annotated frame, without ImageNet pre-training. Our results indicate that using a larger training set is not automatically better, and that for the tracking task a smaller training set that is closer to the target domain is more effective.

Video Object Segmentation with Language Referring Expressions
Most state-of-the-art semi-supervised video object segmentation methods rely on a pixel-accurate mask of a target object provided for the first frame of a video. However, obtaining a detailed segmentation mask is expensive and time-consuming. In this work we explore an alternative way of identifying a target object, namely by employing language referring expressions. Besides being a more practical and natural way of pointing out a target object, using language specifications can help to avoid drift as well as make the system more robust to complex dynamics and appearance variations. Leveraging recent advances of language grounding models designed for images, we propose an approach to extend them to video data, ensuring temporally coherent predictions. To evaluate our method we augment the popular video object segmentation benchmarks, DAVIS'16 and DAVIS'17 with language descriptions of target objects. We show that our approach performs on par with the methods which have access to a pixel-level mask of the target object on DAVIS'16 and is competitive to methods using scribbles on the challenging DAVIS'17 dataset.