

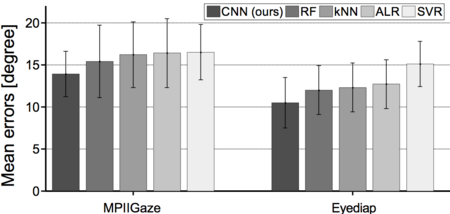
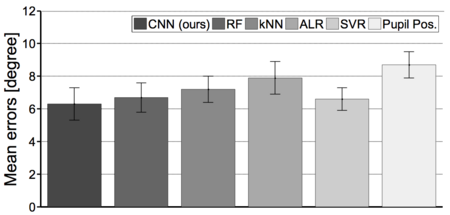
[1] T. Baltrušaitis, P. Robinson, and L.-P. Morency. Continuous conditional neural fields for structured regression. In Computer Vision–ECCV 2014, pages 593–608. Springer, 2014.
[2] J. Li and Y. Zhang. Learning surf cascade for fast and accurate object detection. In Computer Vision and Pattern Recognition (CVPR), 2013 IEEE Conference on, pages 3468–3475. IEEE, 2013.
[3] Y. Sugano, Y. Matsushita, and Y. Sato. Learning-by-synthesis for appearance-based 3d gaze estimation. In Computer Vision and Pattern Recognition (CVPR), 2014 IEEE Conference on, pages 1821–1828. IEEE, 2014.