PrivacEye: Privacy-Preserving Head-Mounted Eye Tracking Using Egocentric Scene Image and Eye Movement Features (MPIIPrivacEye)
Abstract
Eyewear devices, such as augmented reality displays, increasingly integrate eye tracking, but the first-person camera required to map a user's gaze to the visual scene can pose a significant threat to user and bystander privacy. We present PrivacEye, a method to detect privacy-sensitive everyday situations and automatically enable and disable the eye tracker's first-person camera using a mechanical shutter. To close the shutter in privacy-sensitive situations, the method uses a deep representation of the first-person video combined with rich features that encode users' eye movements. To open the shutter without visual input, PrivacEye detects changes in users' eye movements alone to gauge changes in the ''privacy level'' of the current situation. We evaluate our method on a first-person video dataset recorded in daily life situations of 17 participants, annotated by themselves for privacy sensitivity, and show that our method is effective in preserving privacy in this challenging setting.
The full paper can be found here.
The supplementary material can be found here.
Dataset
While an ever-increasing number of eye movement datasets have been published in recent years (see [Bulling et al. 2012, 2011; Hoppe et al. 2018; Steil and Bulling 2015; Steil et al. 2018; Sugano and Bulling 2015] for examples), none of them has been recorded in the context of privacy. We therefore recorded our own dataset. The dataset contains more than 90 hours of data recorded continuously from 20 participants (six females, ages 22-31) over more than four hours each. Participants were students with different backgrounds and subjects with normal or corrected-to-normal vision. During the recordings, participants roamed a university campus and performed their everyday activities, such as meeting people, eating, or working as they normally would on any day at the university. To obtain some data from multiple, and thus also ''privacy-sensitive'', places on the university campus, participants were asked to not stay in one place for more than 30 minutes. Participants were further asked to stop the recording after about one and a half hours so that the laptop's battery packs could be changed and the eye tracker re-calibrated. This yielded three recordings of about 1.5 hours per participant. Participants regularly interacted with a mobile phone provided to them and were also encouraged to use their own laptop, desktop computer, or music player if desired. The dataset thus covers a rich set of representative real-world situations, including sensitive environments and tasks. The data collection was performed with the same equipment as shown in the figure below excluding the camera shutter.
CNN Feature Extraction
Inspired by prior work on predicting privacy-sensitive pictures posted in social networks [Orekondy et al. 2017], we used a pre-trained GoogleNet, a 22-layer deep convolutional neural network [Szegedy et al. 2015]. We adapted the original GoogleNet model for our specific prediction task by adding two additional fully connected (FC) layers. The first layer was used to reduce the feature dimensionality from 1024 to 68 and the second one, a Softmax layer, to calculate the prediction scores. Output of our model was a score for each first-person image indicating whether the situation visible in that image was privacy-sensitive or not. The cross-entropy loss was used to train the model. The full network architecture is shown in the supplementary material. In step size of one second we extracted 68 CNN features from the scene video from the first fully connected layer of our trained CNN model.
Eye Movement Feature Extraction
From the recorded eye movement data we extracted a total of 52 eye movement features, covering fixations, saccades, blinks, and pupil diameter. Similar to [Bulling et al. TPAMI'11] we also computed wordbook (WB) features that encode sequences of n saccades. We extracted these features using a sliding window of 30 seconds (step size of 1 seconds).

Data Annotation
The dataset was fully annotated by the participants themselves with continuous annotations of location, activity, scene content, and subjective privacy sensitivity level. 17 out of the 20 participants finished the annotation of their own recording resulting in about 70 hours of annotated video data. They again gave informed consent and completed a questionnaire on demographics, social media experience and sharing behaviour (based on Hoyle et al. [Hoyle et al. 2014]), general privacy attitudes, as well as other-contingent privacy [Baruh and Cemalcılar 2014] and respect for bystander privacy [Price et al. 2017]. General privacy attitudes were assessed using the Privacy Attitudes Questionnaire (PAQ), a modi ed Westin Scale [Westin 2003] as used by [Caine 2009; Price et al. 2017].
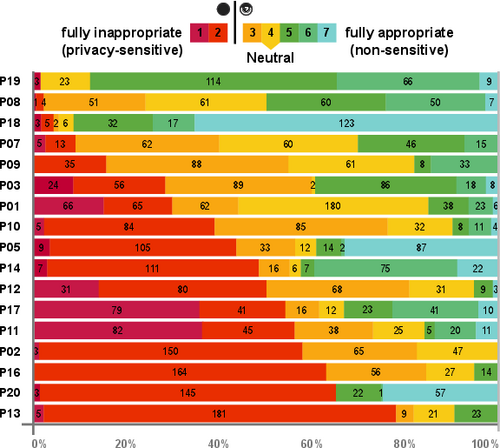
Annotations were performed using Advene [Aubert et al. 2012]. Participants were asked to annotate continuous video segments showing the same situation, environment, or activity. They could also introduce new segments in case a privacy-relevant feature in the scene changed, e.g., when a participant switched to a sensitive app on the mobile phone. Participants were asked to annotate each of these segments according to the annotation scheme (see supplementary material). Privacy sensitivity was rated on a 7-point Likert scale ranging from 1 (fully inappropriate) to 7 (fully appropriate). As we expected our participants to have difficulties understanding the concept of ''privacy sensitivity'', we rephrased it for the annotation to ''How appropriate is it that a camera is in the scene?''. This figure visualises the labelled privacy sensitivity levels for each participant. Based on the latter distribution, we pooled ratings of 1 and 2 in the class ''privacy-sensitive'' (1), and all others in the class ''non-sensitive'' (0).
MPIIPrivacEye Dataset
The full dataset can be downloaded as .zip file but also separately for each participant. Each .zip file contains four folders. In each folder there is a Readme.txt with a separate annotation scheme for the contained files.
Data_Annotation
For each participant and each recording continuously recorded eye, scene, and IMU data as well as the corresponding ground truth annotation are saved as .csv, .npy, and .pkl (all three files include the same data).
Features_and_Ground_Truth
For each participant and each recording eye movement features (52) from a sliding window of 30 seconds and CNN features (68) extracted with a step size of 1 second are saved as .csv, .npy (both files include the same data). These data are not standardised. In a standardised form these data were used to train our SVM models.
Video_Frames_and_Ground_Truth
For each participant and each recording the scene frame number and corresponding ground truth annotation are saved as .csv, .npy (both files include the same data).
Private_Segments_Statistics
For each participant and each recording statistics of the number of private and non-private segments, average, min, max, and total segment time in minutes are saved as .csv, .npy (both files include the same data).
Dataset Download
Please download the full MPIIPrivacEye dataset here (2.6 GB).
Separate downloads:
P1 dataset and annotation (145 MB).
P2 dataset and annotation (156 MB).
P3 dataset and annotation (165 MB).
P5 dataset and annotation (157 MB).
P7 dataset and annotation (149 MB).
P8 dataset and annotation (161 MB).
P9 dataset and annotation (171 MB).
P10 dataset and annotation (163 MB).
P11 dataset and annotation (163 MB).
P12 dataset and annotation (135 MB).
P13 dataset and annotation (163 MB).
P14 dataset and annotation (171 MB).
P16 dataset and annotation (181 MB).
P17 dataset and annotation (167 MB).
P18 dataset and annotation (137 MB).
P19 dataset and annotation (147 MB).
P20 dataset and annotation (160 MB).