Addressing scalability in object recognition
While current object class recognition systems achieve remarkable recognition performance for individual classes, the simultaneous recognition of multiple classes remains a major challenge: building reliable object class models requires a sufficiently high number of representative training examples, often in the form of manually annotated images. Since manual annotation is costly, our research aims at reducing the amount of required training examples and manual annotation for building object class models, thereby increasing scalability. We explore three different ways of achieving this goal.
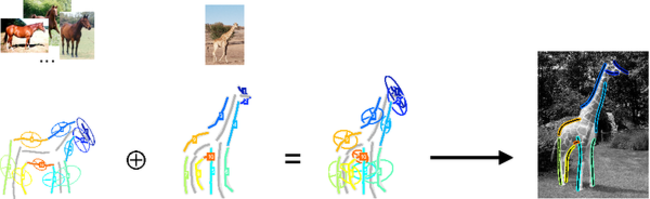
Figure 1.Re-use of model components. The expected variation of the spatial layout of horse parts is combined with a single giraffe example, resulting in a new giraffe object class model (left) that can be used for recognition in an image (right).
Re-using object class model components. In [1], we design a shape-based object class model that allows to re-use previously learned components of one model in order to facilitate the learning of another model, hence increasing scalability. The model represents object classes as assemblies of parts, and captures the local shape of each part as well as their global spatial layout and pairwise symmetry relations (see Fig. 1 for visualizations of horse and giraffe models). Since the corresponding probabilistic formulation includes a distinct factor for each of these constituent model aspects, individual components can be re-used and combined to form new object class models. In particular, given two topologically similar object classes, such as horses and giraffes, the expected variation of the spatial part layout of one class (horse) can be re-used in order to build a model of a second class (giraffe) from just a single training image, as shown in the figure. The part-based nature of our object class representation further allows to re-use model components even for relatively dissimilar classes, such as horses and swans.
According to our probabilistic formulation, object recognition amounts to finding the MAP hypothesis over all possible assignments between model and image features. Since the exact solution to this problem is intractable, we resort to efficient approximate inference techniques instead. Specifically, we use data-driven Markov chain Monte Carlo (DDMCMC) sampling, which allows to guide MAP search by bottom-up part proposals.
In our experimental evaluation, we demonstrate the effectiveness of re-using object class model components for scarce training data, and, at the time of publication of [1], achieve state-of-the-art recognition performance on a standard benchmark data set for shape-based recognition approaches.

Figure 2.Automatically discovered parts of motorbikes and horses. For each object class, corresponding colours denote corresponding part labels.
Automatic discovery of meaningful object parts: While the work presented in [1] relies on the manual selection of re-usable object class components and object parts, a second line of our research focuses on the automatic discovery of meaningful object parts, thereby reducing manual annotation effort. The key technical difference to [1] consists in the treatment of object parts as latent rather than observed variables in a probabilistic formulation.
In [2] , we phrase the problem of finding meaningful parts as inferring latent part labels in a conditional random field (CRF) model, that subsumes discriminative local part classifiers and their spatial layout in a coherent probabilistic framework. In contrast to prior work, we consider parts with flexible shapes and sizes, and marginalize over part occurrences instead of maximization. Further, we allow for and model arbitrary part topologies rather than committing to a single fixed topology. Fig. 2 illustrates automatically discovered parts for horses and motorbikes. Training our object class models involves inferring the values of latent variables, and hence uses the expectation maximization (EM) algorithm. Object recognition in test images proceeds in a sliding window fashion, marginalizing over latent part labels for each potential window using sum-product belief propagation.
In our experiments, we demonstrate superior recognition performance compared to previous work on a variety of different object classes of the challenging Pascal VOC 2007 data set. In particular, we show the benefit of marginalizing over part labels, and learning part shape and topology rather than committing to a fixed layout.
In [3], we explore the decomposition of object class templates based on histograms of oriented gradients (HOG) features into collections of latent topics, using latent Dirichlet allocation (LDA). The decompositions are obtained in a fully data-driven fashion, allowing for the automatic discovery of different viewpoints, object sub-classes, and object parts from training images. The resulting decomposition can further serve as an intermediate representation for object class recognition, in combination with discriminative classifiers. In our experiments, we demonstrate the benefit of this representation over the original HOG template on the Pascal VOC 2006 data set, achieving state-of-the-art performance on several object classes at the time of publication.
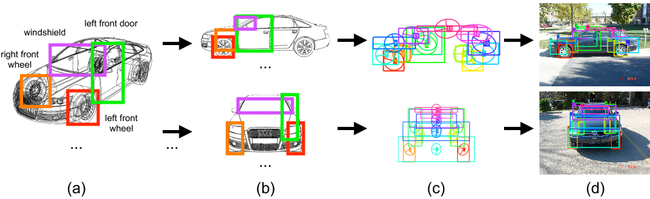
Figure 3. Learning shape models from 3D CAD data. (a) Collection of 3D CAD models composed of semantic parts, (b) viewpoint-dependent, non-photorealistic renderings,(c) learned spatial part layouts, (d) multi-view detection results.
Leveraging alternative knowledge sources: In [4], we propose to accompany visual data in the form of training images by language information, thereby reducing the amount of required training images. Specifically, we explore tutor-driven learning of visual concepts, where the learning of object class models is facilitated by reasoning about spatial relations among various objects observed in a scene, which are asserted by a human tutor. In experiments, we demonstrate our system to successfully recover from ambiguous and even erroneous tutoring.
In [5], we choose to abandon real-world training images altogether, and propose to learn shape models from 3D computer aided design (CAD) models. CAD models provide an accurate and detailed representation of object shape, and hence lend themselves to the learning of object class models. Since they are viewpoint independent, they allow for the generation of artificial training examples from arbitrary viewpoints through rendering. The key challenge consists in bridging the gap between rendered training images and real-world test images, which we achieve by a shape-based abstraction of object appearance. Similar in spirit to [1], we choose a part-based object class representation at the core of our approach, implemented by discriminatively trained part detectors, in connection with a probabilistic model that governs their spatial layout (see Fig. 3). We train separate object class models for each viewpoint, and fuse the detections for multiple viewpoints using a non-maximum suppression technique.
Our approach achieves state-of-the-art recognition performance on a standard benchmark data set for multi-view recognition with respect to both object localization and viewpoint classification, even compared to prior approaches using real-world training images.
References
[1] A Shape-Based Object Class Model for Knowledge Transfer, M. Stark, M. Goesele and B. Schiele, IEEE International Conference on Computer Vision (ICCV), September, (2009) Best Paper Award Honorable Mention by IGD.
[2] Automatic Discovery of Meaningful Object Parts with Latent CRFs, P. Schnitzspan, S. Roth and B. Schiele, IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June, (2010)
[3] Categorical Perception, M. Fritz, M. Andriluka, S. Fidler, M. Stark, A. Leonardis and B. Schiele, Cognitive Systems, Volume 8, (2010)
[4] Multi-Modal Learning, D. Skocaj, M. Kristan, A. Vrecko, A. Leonardis, M. Fritz, M. Stark, B. Schiele, S. Hongeng and J L. Wyatt, Cognitive Systems, Volume 8, (2010)
[5] Back to the Future: Learning Shape Models from 3D CAD Data, M. Stark, M. Goesele and B. Schiele, British Machine Vision Conference (BMVC), September, (2010)