Learning Deep Representations of Fine-Grained Visual Descriptions
Scott Reed, Zeynep Akata, Honglak Lee and Bernt Schiele
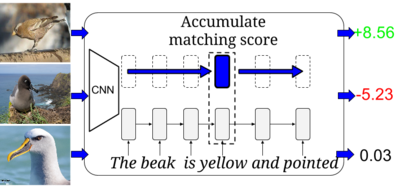
State-of-the-art methods for zero-shot visual recognition formulate learning as a joint embedding problem of images and side information. In these formulations the current best complement to visual features are attributes: manually-encoded vectors describing shared characteristics among categories. Despite good performance, attributes have limitations including (1) finer-grained recognition requires commensurately more attributes; and (2) attributes do not provide a natural language interface. We propose to overcome these limitations by training neural language models from scratch; i.e. without pre-training and only consuming words and characters. Our proposed models train end-to-end to align with the fine-grained and category-specific content of images. Natural language provides a flexible and compact way of encoding only the salient visual aspects for distinguishing categories. By training on raw text our model can do inference on raw text as well, providing humans a familiar mode both for annotation and retrieval. Our model achieves strong performance on zero-shot text-based image retrieval and significantly outperforms the attribute-based state-of-the-art for zero-shot classification on the Caltech-UCSD birds dataset.
Paper, Code and Data
- If you use our code or data, please cite:
@inproceedings {RALS16,
title = {Learning Deep Representations of Fine-Grained Visual Descriptions},
booktitle = {IEEE Computer Vision and Pattern Recognition (CVPR)},
year = {2016},
author = {Scott Reed and Zeynep Akata and Honglak Lee and Bernt Schiele}
}