Semantic Projection Network for Zero- and Few-Label Semantic Segmentation
Yongqin Xian*, Subhabrata Choudhury*, Yang He, Bernt Schiele, and Zeynep Akata
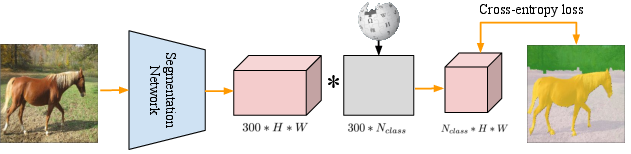
Semantic segmentation is one of the most fundamental problems in computer vision. As pixel-level labelling in this context is particularly expensive, there have been several attempts to reduce the annotation effort, e.g. by learning from image level labels and bounding box annotations. In this paper we take this one step further and propose zero-and few-label learning for semantic segmentation as a new task and propose a benchmark on the challenging COCO-Stuff and PASCAL VOC12 datasets. In the task of zero-label semantic image segmentation no labeled sample of that class was present during training whereas in few-label semantic segmentation only a few labeled samples were present. Solving this task requires transferring the knowledge from previously seen classes to novel classes. Our proposed semantic projection network (SPNet) achieves this by incorporating class-level semantic information into any network designed for semantic segmentation, and is trained in an end-to-end manner. Our model is effective in segmenting novel classes, i.e. alleviating expensive dense annotations, but also in adapting to novel classes without forgetting its prior knowledge, i.e. generalized zero- and few-label semantic segmentation
Paper, Code
- If you find it useful, please cite:
@inproceedings {XianCVPR2019b, title = {Semantic Projection Network for Zero- and Few-Label Semantic Segmentation}, booktitle = {IEEE Computer Vision and Pattern Recognition (CVPR)}, year = {2019}, author = {Yongqin Xian and Subhabrata Choudhury and Yang Heand Bernt Schiele and Zeynep Akata} }