f-VAEGAN-D2: A Feature Generating Framework for Any-Shot Learning
Yongqin Xian, Saurabh Sharma, Bernt Schiele, and Zeynep Akata
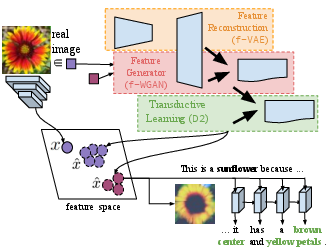
When labeled training data is scarce, a promising data augmentation approach is to generate visual features of unknown classes using their attributes. To learn the class conditional distribution of CNN features, these models rely on pairs of image features and class attributes. Hence, they can not make use of the abundance of unlabeled data samples. In this paper, we tackle any-shot learning problems i.e. zero-shot and few-shot, in a unified feature generating framework that operates in both inductive and transductive learning settings. We develop a conditional generative model that combines the strength of VAE and GANs and in addition, via an unconditional discriminator, learns the marginal feature distribution of unlabeled images. We empirically show that our model learns highly discriminative CNN features for five datasets, i.e. CUB, SUN, AWA and ImageNet, and establish a new state-of-the-art in any-shot learning, i.e. inductive and transductive (generalized) zero- and few-shot learning settings. We also demonstrate that our learned features are interpretable: we visualize them by inverting them back to the pixel space and we explain them by generating textual arguments of why they are associated with a certain label.
Paper, Code (Version 1.0) and Data
- If you find it useful, please cite:
@inproceedings {XianCVPR2019a, title = {f-VAEGAN-D2: A Feature Generating Framework for Any-Shot Learning}, booktitle = {IEEE Computer Vision and Pattern Recognition (CVPR)}, year = {2019}, author = {Yongqin Xian and Saurabh Sharma and Bernt Schiele and Zeynep Akata} }