Multi-Cue Zero-Shot Learning with Strong Supervision
Zeynep Akata, Mateusz Malinowski, Mario Fritz and Bernt Schiele
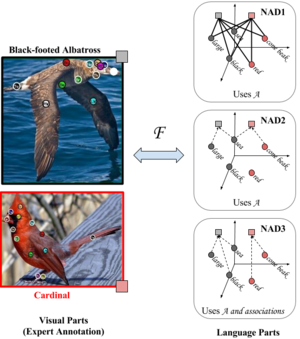
Scaling up visual category recognition to large numbers of classes remains challenging. A promising research direction is zero-shot learning, which does not require any training data to recognize new classes, but rather relies on some form of auxiliary information describing the new classes. Ultimately, this may allow to use textbook knowledge that humans employ to learn about new classes by transferring knowledge from classes they know well. The most successful zero-shot learning approaches currently require a particular type of auxiliary information – namely attribute annotations performed by humans – that is not readily available for most classes. Our goal is to circumvent this bottleneck by substituting such annotations by extracting multiple pieces of information from multiple unstructured text sources readily available on the web. To compensate for the weaker form of auxiliary information, we incorporate stronger supervision in the form of semantic part annotations on the classes from which we transfer knowledge. We achieve our goal by a joint embedding framework that maps multiple text parts as well as multiple semantic parts into a common space. Our results consistently and significantly improve on the SoA in zero-short recognition and retrieval.
Materials
- Paper, Poster, Spotlight Presentation
- Code, Data
- If you use our code, please cite:
@inproceedings {AMFS16,
title = {Multi-Cue Zero-Shot Learning with Strong Supervision},
booktitle = {IEEE Computer Vision and Pattern Recognition (CVPR)},
year = {2016},
author = {Zeynep Akata and Mateusz Malinowski and Mario Fritz and Bernt Schiele}
}